 Solo-Yase
Solo-Yase 

目次
当記事について
Python学習を独学でいろいろ手を出してきた結果、YouTube学習に落ち着きました。
記事という体裁をとっていますが、動画視聴後の復習での振り返り用として主に自分に向けて記事を書いています。
YouTube学習を始めた経緯
YouTubeでは数多のプログラマーの方々が非常に有益な情報を発信してくれています。
そんな多くのチャンネルの中からキノコードさんに辿り着いたのは偶然でした。
動画の解説が自分にとっては分かりやすく、初学者に向けて作成してくれている点も視聴開始のきっかけとなりました。
そのため、YouTube学習はキノコードさんのチャンネルに絞って学習しています。
Youtube:キノコード/プログラミング学習チャンネル
時系列データについて
時系列データ:
- 人口推移データ
- 気温や湿度などの気象データ
- 株価のデータなど
Pandasでは、こうしたデータフレームのインデックスを日付型に変換することで、時系列データとして扱うことができるようになる。
時系列データとして扱うことができるようになることで、指定した日数での集計や、月末だけの集計、週次や月次の集計などを簡単に行うことができるようになる。
また、株価などの経済データを好きな期間で分析することもできる。
移動平均や、指標となる数値を追加すればさらに深い分析まで可能。
データの読み込み
| import pandas as pd pd.options.display.max_rows = 10 pd.options.display.max_columns = None |
取り扱う元データの確認
今回取り扱うデータは実績管理表で、いつ・どの社員が・何を・いくら売り上げたのかがわかるデータになる。
2つのデータの違いは売上日の表記のみとなっている。


sample.csvは売上日がハイフン表記、sample02.csvは売上日が年月日表記となっている。
| df = pd.read_csv(‘sample.csv’, encoding=’utf-8′, header=0) df |
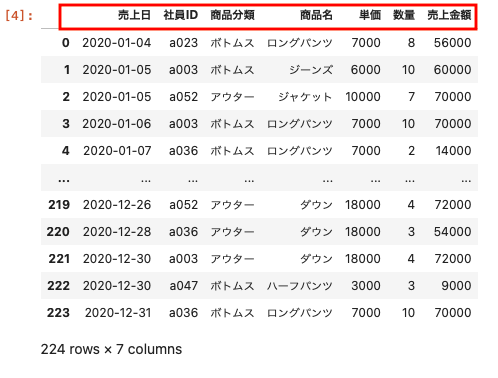
1行目のカラムに売上日や社員IDなどの項目が表示されているため、header=0と記述することで、1行目をカラムとして指定する
データ型の確認
| df.info( ) |
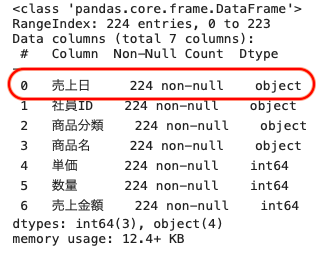
データフレームを確認してみると、インデックスはRangeIndexとなっている。
また、売上日のデータはオブジェクト型、つまり文字列型であることがわかる。
また、単価・数量・売上金額は数値型となっている。
このデータフレームを時系列データとして扱うためにはデータフレームのインデックスが日時のデータになっている必要がある。
現在はRangeIndexとなっているので、売上日がインデックスとなるように記述をしていく。
読み込んだときに自動的に付されるインデックス番号のことで0からはじまる
時系列データへの変換
| df [ ‘売上日 ‘ ] = pd.to_datetime ( df [ ‘ 売上日 ‘ ] ) df [ ‘ 売上日 ‘ ] |
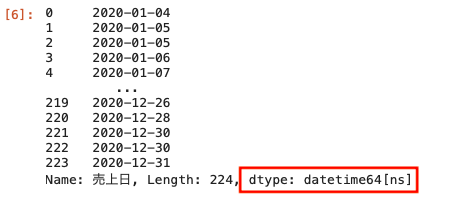
to_datetime関数を使うことで、上記のとおりdatetime64[ ns ] となっている。
datetime64 [ ns ]は日時型のひとつで、Pandasで時系列データを扱うのに適したデータ型といえる。
Pandasの時系列データに適した日時型に変換する関数(astype関数でも変換できるが、今回はto_datetime関数を使用する)
to_datetime関数を使うことで、「/」や「ー」を使って日付として入力されたデータはdatetime64[ ns ]へと変換される。
日時のデータ型になった売上日をインデックスに指定する
| df_2 = df.set_index ( ‘ 売上日 ‘ ) df_2 |
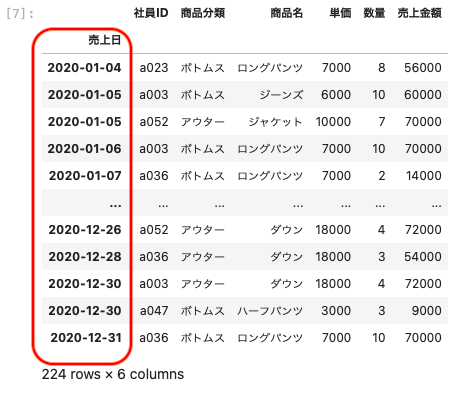
データフレームの情報を確認する
| df_2 . info ( ) |
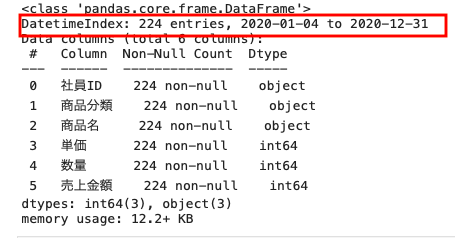
上図のとおり、インデックスのデータ型がdatetimeIndex、つまり日付型のインデックスに変換されていることが確認できた
年月日表記のデータを読み込む
次に売上日が年月日表記になっているデータを読み込んでいく。
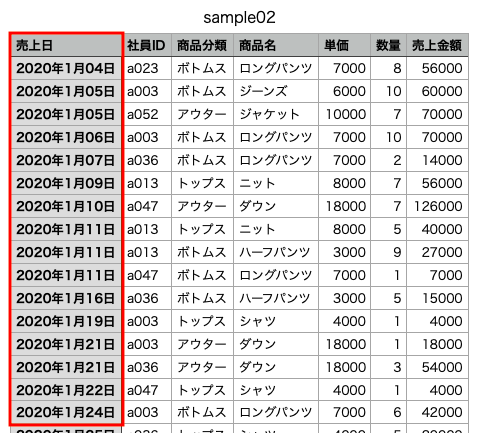
こちらもカラムの1行目に項目が表記されているため、データの読み込みと合わせて1行目をカラムに指定する。
| df02 = pd.read_csv ( ‘ sample02.csv ‘ , encoding = ‘ utf-8 ‘ , header = [ 0 ] ) df02 |
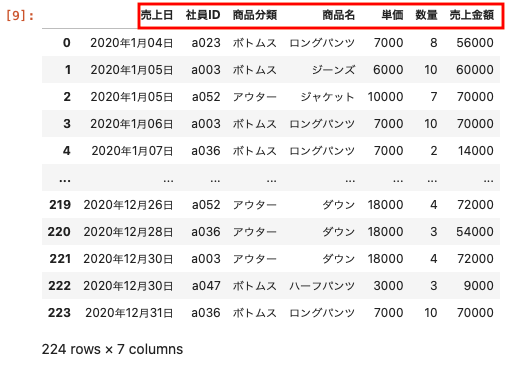
データフレームのデータ型を確認する
| df02.info( ) |
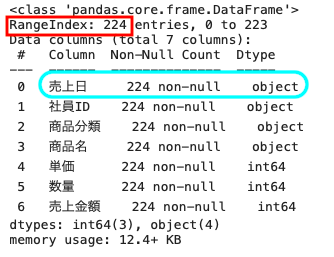
上記のとおり、売上日のデータ型はオブジェクト型、つまり文字列となっている。
これを時系列データとして扱うためにデータ型を日付型に変換する必要がある。
日付型への変換は、to_datetime関数を使って変換を行う。
| df02 [ ‘ 売上日 ‘ ] = pd.to_datetime ( df02 [ ‘ 売上日 ‘ ] ) |
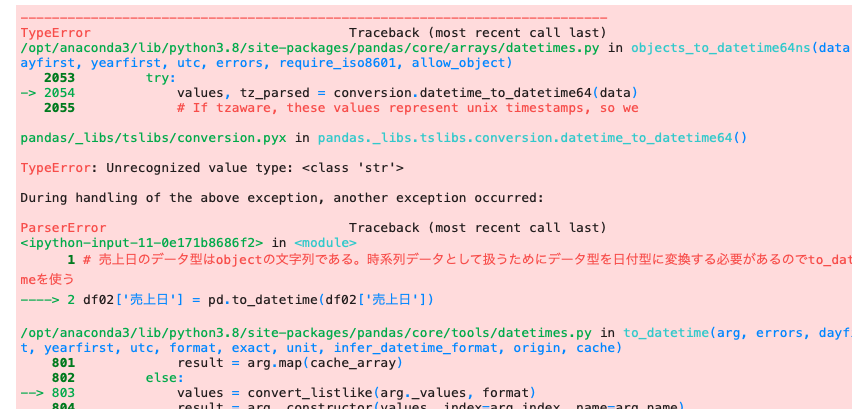
時系列データとしてデータを扱うためにto_datetime関数で変換を行なったが、上記のとおりエラーが出てしまった。
年月日表記の場合には、日付の形式をformatで形式変更してあげる必要がある。
| df02 [ ‘ 売上日 ‘ ] = pd.to_datetime ( df02 [ ‘ 売上日 ‘ ] , format = ‘ %Y年%m月%d日 ‘ ) df02 [ ‘ 売上日 ‘ ] |
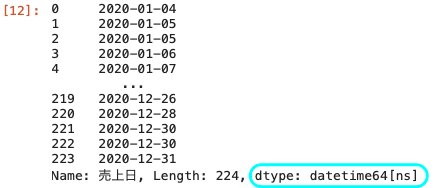
データ型がdatetime64 [ ns ] となっていることが確認できた。
これで売上日をインデックスに指定すれば時系列データとして扱えるようになった。
csv読込時に日時データ型の変換を設定する方法
日時のデータ型の変換は、csvを読み込む時点で設定することができる。
| df = pd.read_csv ( ‘ sample.csv ‘ , encoding = ‘ utf-8 ‘ , header = 0 , parse_dates = True , index_col = ‘ 売上日 ‘ ) df |
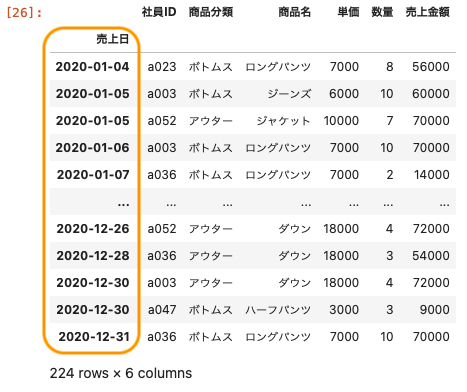
上記のとおり、売上日をインデックスに指定して表示することができた。
読込と同時に日時の列はto_datetime( )で変換するメソッド。
あらかじめデータが分かっている場合には列名をリストで渡しても変換ができる。
年月を指定しての時系列データの抽出
2020年8月のデータのみを抽出する場合には次のように記述する。
| df_2 [ ‘ 2020-08 ‘ ] |
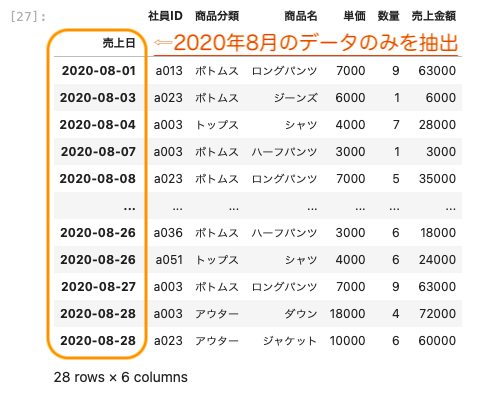
上記のとおり8月のみのデータを抽出することができた。
期間を区切ってデータを抽出する方法
例えば8月15日から9月14日までといったように期間を区切ってデータを抽出したい場合には、スライスを使うことで期間を区切って集計することができる。
| df_2 [ ‘ 2020-08-15 ‘ : ‘ 2020-09-14 ‘ ] |
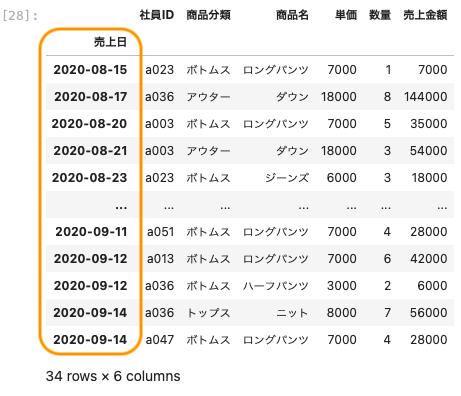
このように8月15日から9月14日までの期間で区切っての集計ができた。
時系列データ:さまざまな集計方法
ここからは期間ごとの集計方法について見ていくことにする。
時系列データにすることで月毎の集計や四半期ごとなどの期間の集計が簡単にできるようになる。
データを簡易的に見ることができるように、次のような売上日と売上金額のデータフレームを用意する。
| df_3 = df [ [ ‘ 売上金額 ‘ ] ] df_3 |
以下、このデータフレームを使ってさまざまな集計方法についてみていくことにする。
resampleメソッドを使っての集計
指定した期間ごとの集計を行うメソッド。Aに集計する期間を文字列で入力する。
- M:月ごと
- Q:四半期ごと
- 10D:10日ごと
また、集計する際にはresample ( ‘ A ‘ ) . sum ( )などのように最後に集計方法を合わせて記述する必要がある。
集計方法を記述しない場合にはデータフレームが生成されないので注意が必要
また、集計時に表示される日付は指定した期間の最終日が表示される
月ごとに合計を集計する
| df_3 . resample ( ‘ M ‘ ) . sum ( ) |
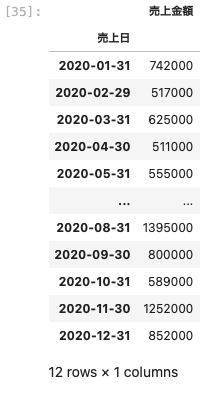
月ごとに合計が集計されている。
前述の通り、集計の日時は月ごとに最終日が表示されている。
四半期ごとに合計を集計する
| df_3 . resample ( ‘ Q ‘ ) . sum ( ) |
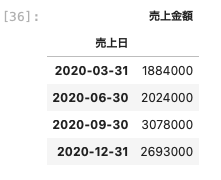
こちらも四半期ごとに合計を集計することができた。
日時については四半期ごとの最終日が表示されている。
10日ごとに合計を集計する
| df_3 . resample ( ‘ 10D ‘ ) . sum ( ) |
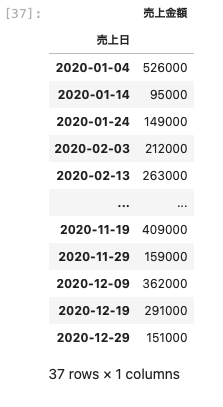
10日ごとに合計を集計することができた。
1月4日からはじまっているのは、元のデータ自体が4日からはじまっているため。
月ごとの平均値を算出する
合計の集計と同様に平均値についても集計することができる。
平均値を集計する場合には集計方法の箇所にmean( )を記述すれば良い
| df_3 . resample ( ‘ M ‘ ) . mean ( ) |

このように平均値についても集計することができた
月ごとの最大値・最小値を算出する
最大値・最小値については集計方法の箇所を変更してあげることで算出することができる。
- max ( ):最大値を集計する
- min ( ):最小値を集計する
| df_3 . resample ( ‘ M ‘ ) . max ( ) |
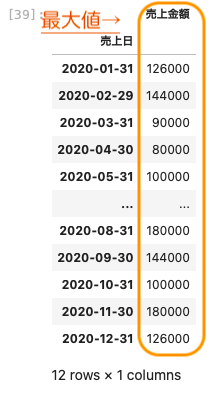
最大値が算出できた。
続いて最小値を算出する。
| df_3 . resample ( ‘ M ‘ ) . min ( ) |
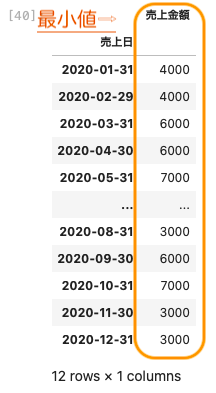
上図のとおり最小値を算出することができた
agg関数を使い複数の集計をまとめて算出する
agg関数を使うことで複数の集計方法をまとめて算出することができる
- mean:平均値を算出する
- max:最大値を算出する
- min:最小値を算出する
- sum:合計を算出する
一度に表示する際には「文字列」のリストで渡せば良い
| df_3 . resample ( ‘ Q ‘ ) . agg ( [ ‘ sum ‘ , ‘ mean ‘ , ‘ max ‘ , ‘ min ‘ ] ) |
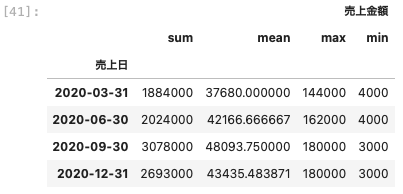
曜日ごとに集計する
インデックスがdatetime64 [ ns ] 型になっているので、インデックスのweekdayを参照することで曜日を0〜6の数値で算出することができる。
- 月曜日:0
- 火曜日:1
- 水曜日:2
- 木曜日:3
- 金曜日:4
- 土曜日:5
- 日曜日:6
| df_3 . index . weekday |

この上記の記述をDataFrameの抽出条件として使うことで、曜日によるデータ抽出が可能になる。
たとえば、月曜日のデータだけを抽出する際には、weekdayを0に指定してデータを抽出する。
| df_3 [ df_3 . index . weekday == 0 ] |

月曜日の平均を算出する方法
| df_3 [ df_3 . index . weekday == 0 ] . mean ( ) |
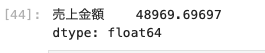
月曜日の指定は0、集計方法はmean ( )で指定してあげればよい。
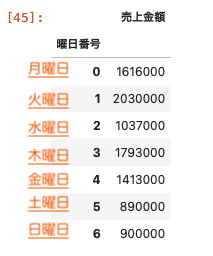
各曜日ごとの集計を同時に出力させる
特定の曜日だけではなく、各曜日ごとの集計を同時に出力させるにはどうしたらよいか。
その場合には曜日番号をインデックスに指定してあげればよい。
- set_index関数:曜日番号をインデックスに変更できる
- index.name:名前を曜日番号に変更することができる
- sort . index:インデックス名を並べ替える
| df_4 = df_3 . set_index ( df_3 . index . weekday ) df_4 . index . name = ‘ 曜日番号 ‘ df_4 . sum ( level = ‘ 曜日番号 ‘ ) . sort_index ( ) |
まとめ
時系列データとしてデータ型を変換することでできる集計が増えたのにはびっくりした。
売上日や売上金額がデータ型かどうかを確認して変換する必要はあるが、間違いを防ぐ意味でもしっかりと確認を行うようにする。

