 Solo-Yase
Solo-Yase 

目次
当記事について
Pythonを学習しはじめて以来、書籍やオンライン学習などいろいろ手を出してきました結果、現在はYouTube学習に落ち着きました。
動画視聴後の復習およびコードの書き方や結果表示を毎回動画視聴するのが大変なため、振り返り用として主に自分に向けて記事を書いています。
YouTube学習を始めた経緯
YouTubeでは数多のプログラマーの方々が非常に有益な情報を発信してくれています。
そんな多くのチャンネルの中からキノコードさんに辿り着いたのは偶然でした。
動画の解説が自分にとっては分かりやすく、初学者に向けて作成してくれている点も視聴開始のきっかけとなりました。
そのため、YouTube学習はキノコードさんのチャンネルに絞って学習しています。
Youtube:キノコード/プログラミング学習チャンネル
Excel作業を効率化するためにPythonを使う
Pythonでできることはいろいろあるが、自分にとって必要になりそうなもの、できたら役に立ちそうなものは次の3つ。
- ①エクセル作業の効率化
- ②Webスクレイピング
- ③データの分析
今回は、この中からエクセル作業の効率化について、Excelの読込から書き出しまでひととおりを整理していく
Excelファイルの読込
まずはじめにライブラリをインストールする
よく使う機能や関数をまとめて簡単に使えるようにした便利なもの
csvファイルやExcelファイルを読み取るための機能や、データを表にする機能、グラフにする機能などがあるライブラリ。
Pandasが取り扱うデータ構造は次の2つ。
① Series:1次元データ(データ構造が1列)
②DataFrame:2次元データ(データ構造が2列以上)
PythonからExcelを操作することができるライブラリ
特定の条件に一致するファイルを取得できるライブラリ
| !pip install openpyxl import openpyxl import pandas as pd import glob |
上記記述で、openpyxl、pandas、globの3つを読み込む
つづいて、読み取るファイルのパスやシート名、書き出すファイルのパス名を作成する。
この際に、変数に代入する形で作成することで、次回同様の操作を行うときに、この部分だけを書き換えるだけで良くなるので、非常に便利。
| # 読み取るファイルのパスを作成 impor_file_path = ‘ sample.xlsx ‘ # 編集したいシート名 excel_sheet_name = ‘ 発注管理表 ‘ # 書き出すファイルのパスを作成 export_file_path = ‘ /pandas06/output’ |
Excelファイルをデータフレームとして読み込む
| df_order = pd.read_excel (import_file_path, sheet_name = excel_sheet_name ) |
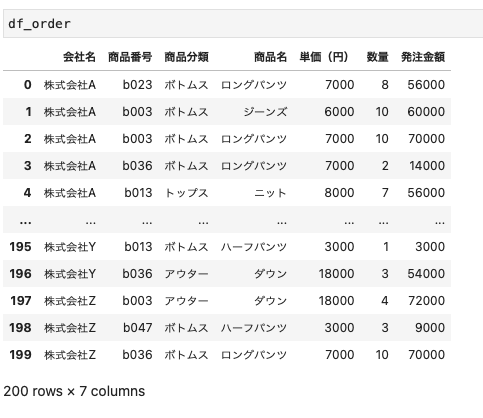
Excelファイルを読み込むことができた。
DataFrameから1列取り出すとデータの種類が変わる
このファイルの会社名の部分に注目して見てみると、
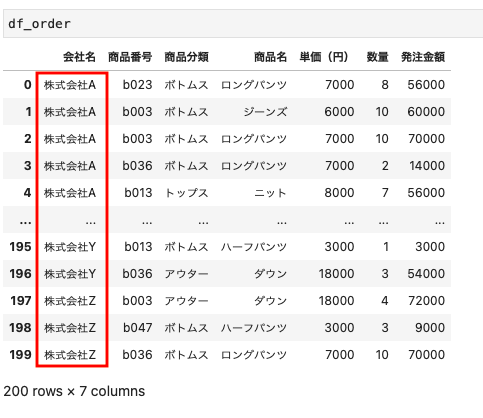
このように株式会社A,株式会社A・・・株式会社Z、株式会社Zといったように同じ会社名が並んでいる。
このように重複した会社名をユニーク(一意)にして取得する
| company_name = df_order[ ‘ 会社名 ‘ ] . unique( ) company_name |

このように重複していないユニークの会社名を取得することができた。
このユニークとして取得したデータはnumpyの配列という意味をもっている。
もともとのデータはデータフレームなので、データフレームから1列だけ取り出すとデータの種類が変わる、ということは覚えておく。
会社名ごとにデータを分割してデータを取得する
| df_order [ ‘ 会社名 ‘ ] == ‘ 株式会社A ‘ |
この記述は、【df_orderというデータフレームのカラム名「会社名」の中から、株式会社Aと一致するもの】という意味になる
この記述を実行すると次のようにブール値が返ってくる。
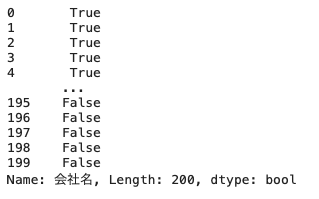
株式会社Aと一致する箇所についてはTrueが、そうでない箇所についてはFalseが返ってきていることがわかる
これを利用して株式会社Aのデータだけを抽出するには、次のように記述すればよいということになる
| df_order[ df_order [ ‘ 会社名 ‘ ] == ‘ 株式会社A ‘ |
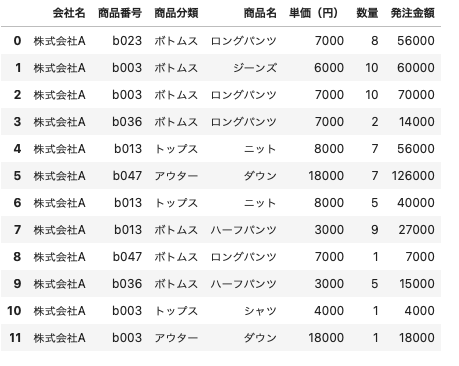
このように株式会社Aだけのデータを取得することができた
for構文を使って会社名ごとにデータを分割する
会社名ごとに分割する
| for i in company_name: print( i ) |

このようにfor構文を使うことで会社名を取得することができた
これを利用して、取得した会社名に該当するデータをそれぞれ取得する記述は次のようになる
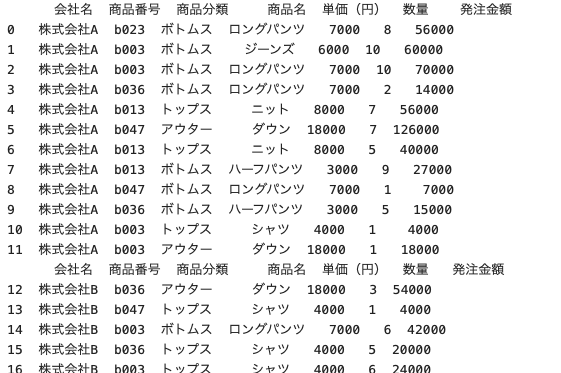
| for i in company_name: df_order_company = df_order [ df_order [ ‘ 会社名 ‘ ] == i ] print ( df_order_company ) |
この記述をすることで、company_nameから会社名を1つずつ取り出して変数iに代入していく。
2行目では変数iに一致する会社名のデータフレーム、という名前で変数に代入されていく
3行目は、それぞれ取得したデータ一覧、ということになる。
Excelファイルの書き出し
上記で取得したデータをExcelファイルとして書き出す方法
| for i in company_name: df_order_company = df_order [ df_order [ ‘ 会社名 ‘ ] == i ] df_order_company . to_excel ( export_file_path + ‘ / ‘ + i + ‘ . xlsx ‘ ) |
Excelファイルを書き出す関数

以上のようにfor構文を使うことで会社名ごとにデータを分割し、それぞれデータを書き出すことができた
分割したファイルを結合する
分割したファイルの読み込みを行う
これまで会社名ごとにデータを分割して保存するまでを行なってきたが、今度は分割してあるデータを1つに結合させる方法について学習する。
上記には分割されているデータが保存されているoutputフォルダがある。その横のrawdataフォルダには分割してあるデータを結合した際に保存するフォルダとして新しく作成したものになる。
| # 結合させたファイルを書き出すパスを作成する export_file_path = ‘ / pandas06/ rawdata ‘ # 分割したファイルが保存されているファイルのパスを作成する import_file_path = ‘ / pandas06/ output ‘ # 分割したファイルが保存されているフォルダの全てのファイルを読み込む path = import_file_path + ‘ / ‘ + ‘ * . xlsx ‘ |
Pythonでは*(アスタリスク)には全てという意味をもつため、*.xlsxと記述することで、拡張子がxlsxのもの全てという意味をもつ
| file_path = glob . glob ( path ) |
glob:特定の条件に一致するファイル名を取得することができるライブラリ
以上より、拡張子xlsxとなっているExcelファイル全てという条件に一致するファイル名を取得する、という意味になる

このように拡張子xlsxのファイルを全て読み込むことができた
読み込んだファイルをデータフレームとして表示する
上記のfile_pathには読み込んだ会社名ごとのファイルが格納されている。
それらをfor構文で会社名ごとに取得して、データフレームに代入していく
データフレームに代入できるように、まずはじめに空のデータフレームを先に作成し、そのあとにfor構文を使って会社名ごとのExcelファイルを読み込んでいくと、次のようになる。
| # 空のデータフレームをまず作成する df_concat = pd . DataFrame( ) # for構文で会社名ごとにExcelファイルの読み込みを行う for i in file_path: df_read_excel = pd . read_excel ( i ) print ( df_read_excel . head ( 3 ) ) |
読み込んだ会社名ごとのデータがどうなっているのかの確認で、最初の3行だけを表示させてみると次のように表示される

会社名ごとにデータが取得できていることがわかった。
これらのデータを1つに結合させてデータフレームで表示させるにはこのように記述する
| df_concat = pd . DataFrame( ) for i in file_path: df_read_excel = pd . read_excel ( i ) df_concat = pd.concat ( [ df_read_excel, df_concat] ) |
データを結合することができる関数
ここでは会社名ごとに読み込んだExcelファイルと空のデータフレームを結合させてデータフレームに格納していくイメージ
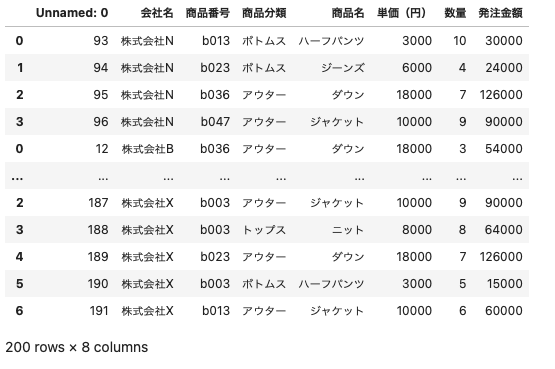
このように1つに結合することができた。
不必要なカラムを削除する
結合したデータフレームには、Unnamedという不必要なカラムが追加されているため、これを削除するために、次のように記述する
| df_drop = df_concat . drop ( ‘ Unnamed: 0 ‘ , axis = 1 ) df_drop . head ( 3 ) # 削除した結果を3行だけ表示 |
データフレームの列や行を削除することができる関数
drop ( A , axis = ( 1 or 0 ) )
Aは削除したい項目
axis = 1の場合:列方向で削除
axis = 0の場合:行方向で削除
となるため今回の例では、Unnamedの列を削除、という意味となる

このように不必要なUnnamedの列が削除されていることが確認できた
データフレームの並べ替え
発注金額ごとに並べ替えを行う
データフレームは項目を決めて並べ替えを行うことができる
今回は発注金額の多い順に並べ替えを行なっていく
| df_sort = df_drop . sort_values ( by = ‘ 発注金額 ‘ , ascending = False ) df_sort |
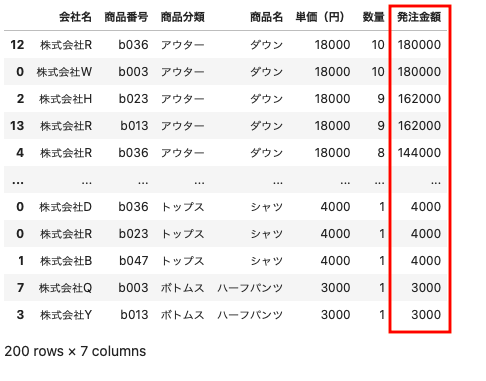
以上のように発注金額が多い順に並べ替えを行うことができた
データフレームの並べ替えを行う関数
ascending = False:降順(多い順から表示)
ascending = True:昇順(小さい順に表示)
ファイルを書き出して保存する
| df_sort . to_excel ( export_file_path + ‘ / ‘ + ‘ 結合した一覧表 . xlsx ‘ ) |
このように記述することで「結合した一覧表」の名前でファイルを書き出すことができる。
該当のフォルダにファイルの書き出しができていることが確認できた。
このファイルを開いてみる。
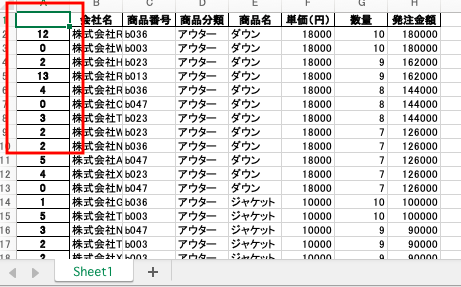
このようにファイルの一部に不必要な列があるため、これを削除して別名で保存する
| workbook = openpyxl . load_workbook ( export_file_path + ‘ 結合した一覧表 . xlsx ‘ ) worksheet = workbook . worksheets [ 0 ] worksheet . delete_cols ( 1 ) workbook . save ( export_file_path + ‘ 結合した一覧表01 . xlsx ‘ ) |
以上のように記述することで次のような結果となる
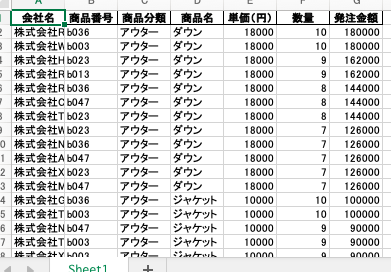
不必要な列が削除されていることが確認できた。
load_workbook:Excelファイルを読み込む関数
worksheets[0]:[.0 ]は最初のシート、という意味
delete_cols ( 1 ) :指定した(列番号)を削除する。ここでは列番号1を削除という意味
save:ファイルを保存する関数
まとめ
今回は、読み込んだExcelファイルを会社名ごとに分割してデータを書き出し、また分割されたExcelファイルをひとつに結合させる方法について学習した。
Excel自体は仕事でも使う場面があるため、データの読み込み、書き出しについてはしっかりと使えるように書き方をマスターしていく。
説明の中で疑問に感じたことは、分割されたデータを結合する際、元データは株式会社Aから順になっていたが、結合データはバラバラになってしまっていたこと。
これについては方法はあると思うので、別の動画で出てきた際には合わせて使えるようにしたい
Excelの使い方についてはかなり自己流で使ってきたため、この機会にPythonでコードの記述をできるようにして、データの可視化など役に立てていけるようにしたい。
今回の内容ではあまり曖昧な点はなかった。

