 Solo-Yase
Solo-Yase 

目次
当記事について
Python学習を独学でいろいろ手を出してきた結果、YouTube学習に落ち着きました。
記事という体裁をとっていますが、動画視聴後の復習での振り返り用として主に自分に向けて記事を書いています。
YouTube学習を始めた経緯
YouTubeでは数多のプログラマーの方々が非常に有益な情報を発信してくれています。
そんな多くのチャンネルの中からキノコードさんに辿り着いたのは偶然でした。
動画の解説が自分にとっては分かりやすく、初学者に向けて作成してくれている点も視聴開始のきっかけとなりました。
そのため、YouTube学習はキノコードさんのチャンネルに絞って学習しています。
Youtube:キノコード/プログラミング学習チャンネル
PandasのDataFrameやSeriesの並び替えについて
Pandasでできる並び替え一覧
- 小さい順からの並び替え
- 大きい順からの並び替え
- 2つ以上の列の並び替え
- 行方向の並び替え(これはExcelやSQLではできない)
データの読み込み
| import pandas as pd pd.set_option( ‘ display . max_columns ‘ , None ) pd.set_option( ‘ display . max_rows ‘ , 10 ) |
もう何度もコードを書いている気がするが、このset_optionは、これから表示する表の表示設定を変更する関数。
今回は表示列数は無制限(None)に、表示行数は10行に設定する。
今回使うデータの内容を確認する。
今回扱うデータは下記のような販売データになります。誰が、どの商品を、いつ、どれだけ売上げたかが分かるようになっています。
Pandas④CSV・Excelファイルの読み込みの項でも、Excelファイルは、read_excelで読み込むことができると学習している。
今回は新たに、Excelシートを指定してのデータ読み込みができることを学習する。
シート名を指定してExcelファイルを読み込む
| df = pd.read_excel ( ‘ sample.xlsx ‘ , sheet_name = ‘ 実績管理表 ‘ ) df |
DataFrameの並び替えについて
売上金額を昇順に並び替える
| df.sort_values ( by = ‘ 売上金額 ‘ ) |
Aのカラムを小さい順に並び替える
- 昇順:小さいものから大きいものへ並び替える
- 降順:大きいものから小さいものへ並び替える
- 昇順=数値:1〜100の順番
- =平仮名やカタカナ:あ、い、う〜わ、を、んの順番
- =アルファベット:a , b , c 〜 x, y, zの順となる
- 降順=数値、平仮名、アルファベット:上記の逆となる
売上金額を降順に並び替える
- ascending = False : 降順
- ascending = True : 昇順
| df.sort_values ( by = ‘ 売上金額 ‘ , ascending = False ) |
また、昇順に並び替える際には
ascending = True
と記述すれば良いのだけれど、何も書かない状態でも昇順になったことから、どちらでも良いのかもしれない。
2つのカラムを並び替える
氏名と売上金額を昇順に並び替える
| df.sort_values ( by = [ ‘ 氏名 ‘ , ‘ 売上金額 ‘ ] ) |
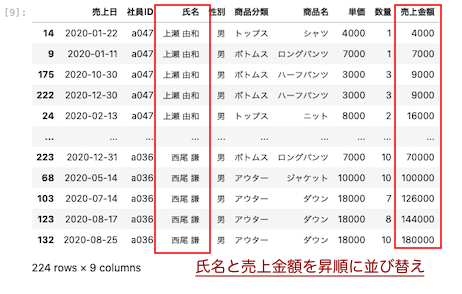
by = [ 引数 ] :引数をリストにして渡すと、2つのカラムの並び替えができる
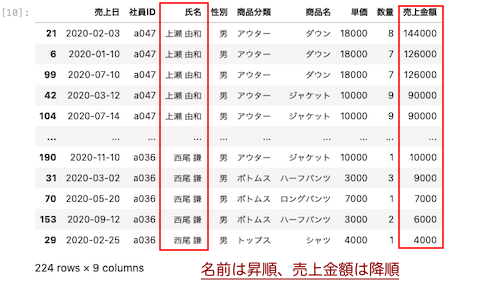
氏名を昇順、売上金額を降順に並び替える
上記で学習した2つのカラムの並び替えと、昇順・降順を指定するascending=を一緒に記述することで、カラム名を指定しつつ、昇順・降順も指定することができる。
| df.sort_values ( by = [ ‘ 氏名 ‘ , ‘ 売上金額 ‘ ] , ascending = [ True, False ] |
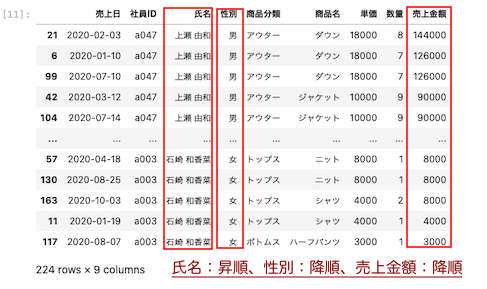
3つのカラムを並び替える
性別を降順、氏名を昇順、売上金額を降順に並び替えるには、上記のリストに3つめを指定してあげればよい。
| df.sort_values ( by = ‘ 性別 ‘ , ‘ 氏名 ‘ , ‘ 売上金額 ‘ ] , ascending = [ False, True, False ] ) |
欠損値の取り扱い
セル内に空白がある場合
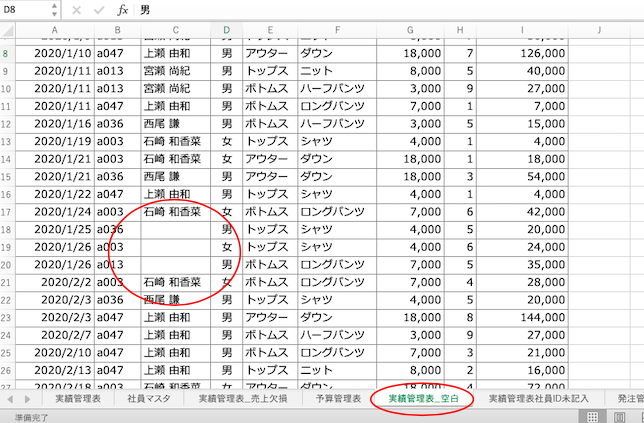
氏名のセル内に空白がある場合に氏名を昇順で表示するとどうなるか。
| df = pd.read_excel ( ‘ sample.xlsx ‘ , sheet_name = ‘ 実績管理表_空白 ‘ ) df.sort_values(by = ‘ 氏名 ‘ , ascending = True ) |
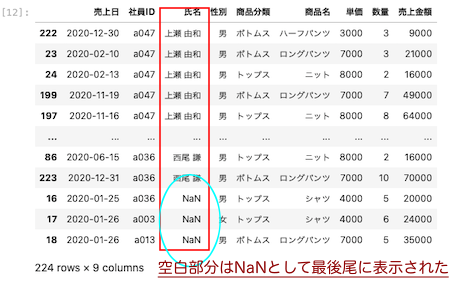
上記のように、欠損値は最後に表示された。
欠損地があるデータを降順で並び替えた場合
| df.sort_values ( by = ‘ 氏名 ‘ , ascending = False ) |
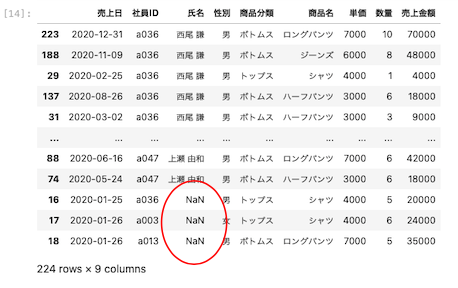
降順で並び替えた場合も欠損値のNaNは最後に表示された。
欠損値を先頭にして、氏名を降順に並び替える
では、欠損値を一番先頭に表示させるにはどうすればよいか。
次のように記述すると、欠損値を先頭に表示することができる
| df.sort_values ( by = ‘ 氏名 ‘ , ascending = False, na_position = ‘ first ‘ ) |
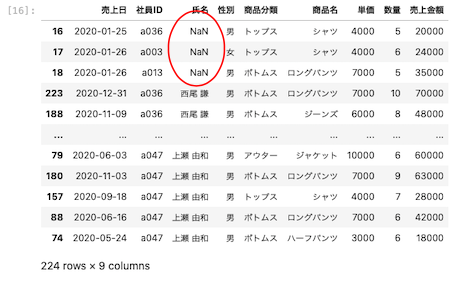
行方向の並び替えを行う
axisメソッド:行の中で並び替えをする
先ず、文字と数値が混在するデータは並び替えができないことに注意する。
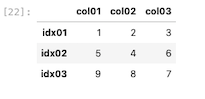
そのため、ここからは新たにデータフレームを作成して並び替えを行なっていく
| df_ax = pd.DataFrame( { ‘ col01 ‘ : [1, 5, 9], ‘ col02 ‘ : [2, 4, 8], ‘ col03 ‘ : [3, 6, 7] } , index = [ ‘ idx01 ‘ , ‘ idx02 ‘ , ‘ idx03 ‘ ] ) df_ax |

| df_ax.sort_values ( by = ‘ idx01 ‘ , ascending = False, axis = 1 ) |

axis = 1:行を指定する
axis = 0:列を指定する(デフォルトで0が指定されている)
axisに0を渡すと列の並び替えをする
| df_ax.sort_values ( by = ‘ col01 ‘ , ascending = False, axis = 0 ) |

idx02の行を降順に並び替える
| df_ax.sort_values( by = ‘ idx02 ‘ , ascending = False, axis = 1 ) |

元のデータフレームを変更する
これまで何度か行や列を指定して並び替えを行なってきたが、元々のデータフレームを表示してみるとどうなっているのかを一度確認する。
| df_ax |
このように元のデータ自体は並び替えされていないことが分かった。この元データ自体が変更されるようにコードを記述していく。
| df_ax.sort_values ( by = ‘col01 ‘ , ascending = False, inplace = True ) df_ax |
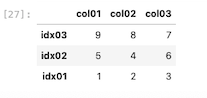
元のデータ自体を変更する
引数inplaceを使わずに元のデータフレームを並び替える方法
は、もう一度同じ変数に代入してあげることで解消する
| df_ax = df_ax.sort_values( by = ‘ col01 ‘ , ascending = True ) df_ax |
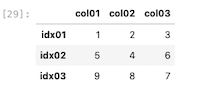
インデックスを降順に並び替える場合
| df_ax.sort_index( ascending = False ) |

- sort_values:データを昇順・降順に並び替える
- sort_index:インデックス(行名・列名)で並び替える
sort_valuesでは列名や行名を指定したが、sort_indexでは指定する必要はない
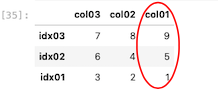
インデックスを降順に並び替え、元データに上書きし、欠損値を先頭に表示させる
| df_ax.sort_index( ascending = False, inplace = True, na_position = ‘ first ‘ ) df_ax |

カラムを並び替えて、降順に表示させる
| df_ax.sort_index ( axis = 1, ascending = False ) |
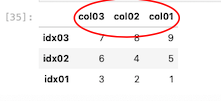
Seriesの要素を並び替える
DataFrameから1列取り出すとSeriesになる
| s = df_ax [ ‘ col01 ‘ ] s |
もとのデータはこちら。
このcol01の列だけを取り出してみると次のように表示される。

取り出したsのデータ型も確認してみる。
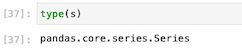
以上のようにデータフレームから1列取り出すと、シリーズになっていることが分かる。
Seriesも並び替えることができる
sを昇順に並び替えてみる
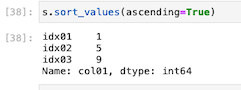
上図のとおり昇順に並び替えることができた。
まとめ
今回はデータの並び替えについて学習した。
自分の欲しい項目だけを取り出してデータを並び替えることができるようになると、より便利にデータフレームを扱うことができそうだな、というのはコードを記述しながら実感することができた。
データを上書きするinplace_Trueの記述だけはまだしっくりときていない。
まずは、自分が日々統計をしているデータでも同じように並び替えができるかを確認しつつ、復習をしていきたいと思う。

