 Solo-Yase
Solo-Yase 

目次
当記事について
Python学習を独学でいろいろ手を出してきた結果、YouTube学習に落ち着きました。
記事という体裁をとっていますが、動画視聴後の復習での振り返り用として主に自分に向けて記事を書いています。
YouTube学習を決めた経緯
YouTubeでは数多のプログラマーの方々が非常に有益な情報を発信してくれています。
そんな多くのチャンネルの中からキノコードさんに辿り着いたのは偶然でした。
動画の解説が自分にとっては分かりやすく、初学者に向けて作成してくれている点も視聴開始のきっかけとなりました。
そのため、YouTube学習はキノコードさんのチャンネルに絞って学習しています。
Youtube:キノコード/プログラミング学習チャンネル
Pandasとは
データ解析を支援する機能を提供するPythonのライブラリ
- csvファイルを読み取るための機能
- Excelデータを読み取る機能
- 列や行を削除したり計算したりする
- フィルターをかけてデータを抽出する
- グループごとにまとめる
- 表同士ののデータを結合する
- 欠損値のあるデータを埋める
- 時系列データを扱う
- グラフ化する
このようにExcelでできることがほぼ可能。データベース言語のSQL(SQLは未学習)でできることもほぼできる便利なライブラリである。
そのため、PandasができるようになるとExcel操作など日々の業務効率化や人工知能開発までできるようになる。
DataFrameとSeries
Pandasで扱うデータ構造には次の2つがある。
- データフレーム
- シリーズ
データフレーム
Excelの表形式のように、行と列で成り立つイメージ
シリーズ
データフレームから1列取り出したときにできる型。
Pythonでいうところのリストのようなものにindexがついているイメージ
Pandasをインポートする
csvファイルを読み込んでデータフレームを作成する
※使用するデータ:政府が発表している1920年から2015年までの全国の人口推移データ
Pandasをインポートしてcsvファイルを読み込む
| import pandas as pd |
asを記入することでpandasをpdとして使うことができる
| df_population_data = pd.read_csv(‘data.csv’, encoding=’shift-jis’) |
| df_population_data |
read_csv関数:インデックスにする列を指定したり、読み取る列を指定したり、列営をスキップして読み取ったり、文字コードを指定したりすることができる。
df_population_dataを実行すると次のような表が出来上がる
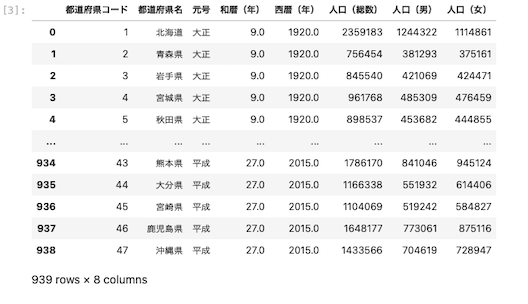
データ型を確認する
| type(df_population_data) |
| pandas.core.frame.DataFrame |
いろいろな書き方
表示している設定を変更する
| pd.set_option(‘display.max_rows’, 1000) |
set_optionで設定を変更することができる。上記のコードでは画面に最大1000行まで表示させるという意味。
データが大きいため、ここでは画像は割愛する。
変更した設定を元に戻す
| pd.reset_option(‘display.max_rows’) |
reset_option:設定をもとにもどしてくれる
最大表示列数を変更する
| pd.set_option(‘display.max_columns’, 5) |
| df_population_data |
このように書くと列数を変更することができる。
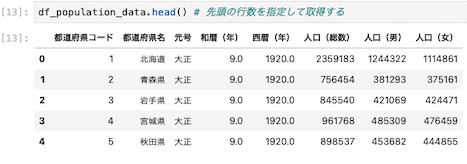
先頭の行数を指定してデータを取得する(デフォルトでは5行)
| df_population_data.head() |
head()をつかうことで先頭の5行を指定して表示してくれる
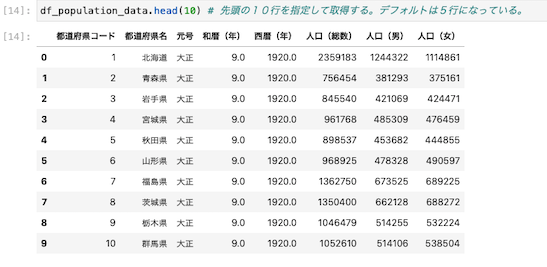
先頭の10行を指定して取得する場合は、head(10)と記入する。
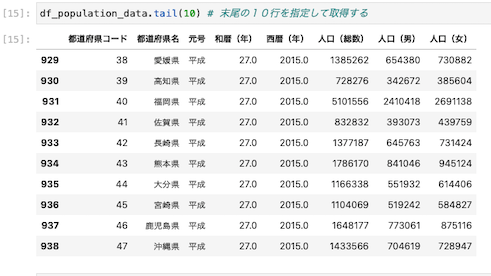
末尾の10行を指定して取得する
| df_population_data.tail(10) |
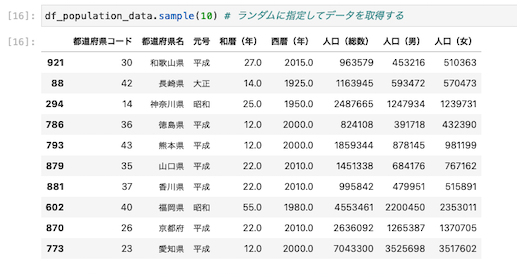
ランダムに10行指定してデータを取得する
| df_population_data.sample(10) |
データフレームの情報を取得する
| df_population_data.info() |
info()と入力することで、データフレームの情報を取得することができる。
型・行数・列数・列名・各列のデータ型・使用しているメモリなど
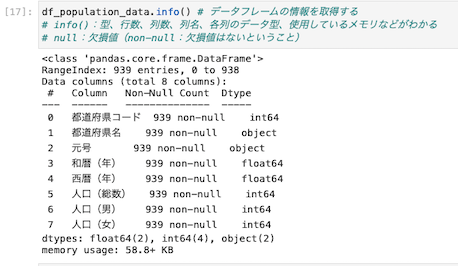
取得したデータ内にnon-nullとあるが、これはデータ内に欠損値がないことを示している
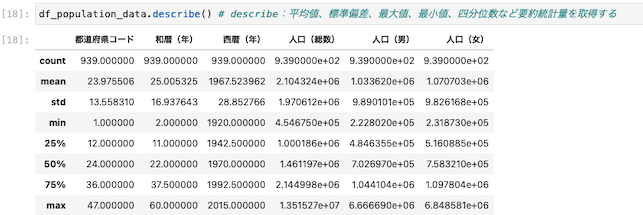
要約統計量を取得する
| df_population_data.describe() |
- 平均値
- 標準偏差
- 最大値
- 最小値
- 四分位数
以上のような項目を取得する
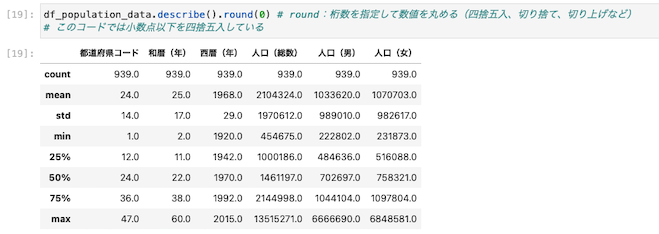
桁数を指定して数値をまるめる
上記の抽出したデータは桁数が大きいため数字がみづらくなっている。
そのため、桁数を指定(四捨五入等)して数値を見やすく設定を変更する
| df_population_data.describe().round(0) |
round()関数:桁数を指定して数値をまるめることができる。
まるめる→(四捨五入・切り捨て・切り上げなど)
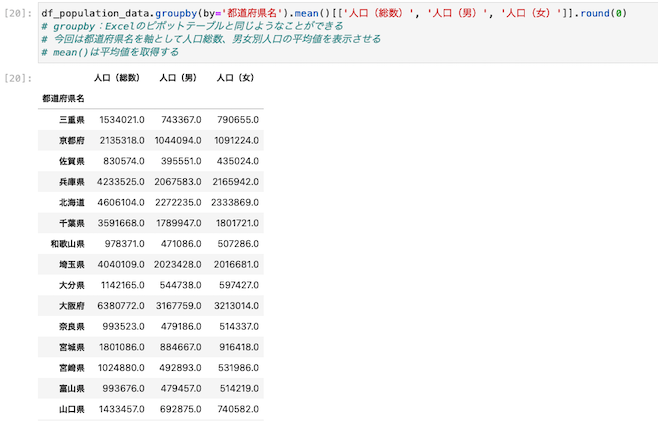
Excelのピボットテーブルと同じようなこともできる
groupbyを使うとピボットテーブルと同じようなことができる
| df_population_data.groupby(by=’都道府県名’).mean()[[‘人口(総数)’, ‘人口(男)’, ‘人口(女)’]].round(0) |
都道府県名を主軸として、人口総数、男女別人口の平均値を表示させる。
データフレームの並べ替えをする
| df_population_mean = df_population_data.groupby(by=’都道府県名’).mean()[[‘人口(総数)’, ‘人口(男)’, ‘人口(女)’]].round(0) |
| df_population_mean.sort_values(by=’人口(総数)’, ascending=False) |
sort_valuesと書くことで、対象(ここでは人口(総数))を多い順に並べ替えることができる
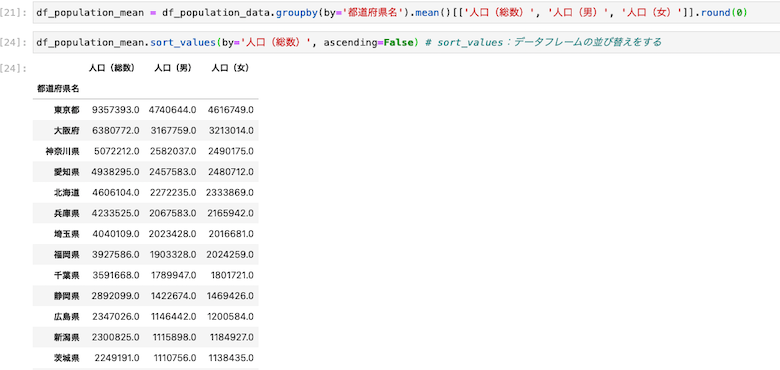
ちなみにascending=Falseの部分を、ascending=Trueと書き換えると、人口総数の少ない順に並べ替えることができる。
データ同士を結合する方法
2つのデータがあり、それぞれのデータにはいくつか共通する項目があると仮定し、次のようなデータフレームを仮に作成してみる。
| left = pd.DataFrame({‘name’:[‘aaa’, ‘bbb’, ‘ccc’, ‘ddd’], ‘age’:[24, 33, 27, 42]}) |
| right = pd.DataFrame({‘name’:[‘eee’, ‘bbb’, ‘aaa’, ‘fff’, ‘ddd’], ‘group’:[‘x’, ‘y’, ‘y’, ‘x’, ‘x’]}) |
このコードは次のようなものである


mergeメソッドでデータフレームを結合する
| pd.merge(left, right) |
leftとrightの両方に存在するnameをキーとしてデータを結合する

結合されたデータは2つのデータに共通するキーであるnameを軸に結合されたが、片方にしかデータがないものについては結合されていない
そのため、どちらか片方にデータがあるものについても結合するようにコードを書き換える。
| pd.merge(left, right, how=’outer‘) |
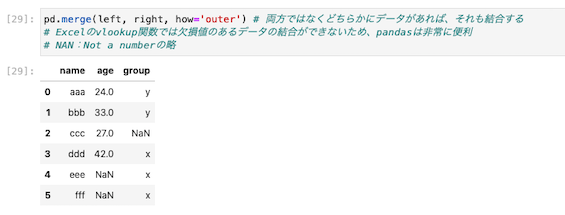
Excelのvlookup関数ではこのような欠損値(どちらか片方にしかデータがない)のあるデータは結合できないため、その点Pandasは非常に便利
表内にあるNANとは、Not a numberの略らしい
concat関数を使ってデータを縦に結合する
| pd.concat([left, right]) |

concat関数を使ってデータを横に結合する
| pd.concat([left, right], axis=1) |
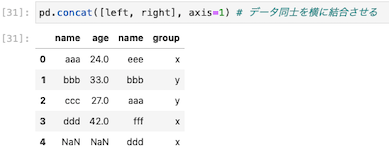
データを縦に結合したときのコードと異なるのは、文末にaxis=1が追加されたこと。
現時点ではこの表記がどのような意味を示しているのかは不明だが、縦から横への結合ができた。
matplotlibを使ってデータをグラフ化する
可視化するためにまずは次のコードを記述する。
| %matplotlib inline import matplotlib matplotlib.rcParams[‘font.family’] = ‘Arial Unicode MS’ |
jupyter labでデータを可視化するために、matplotlibと日本語表記に変換するコードを記述する
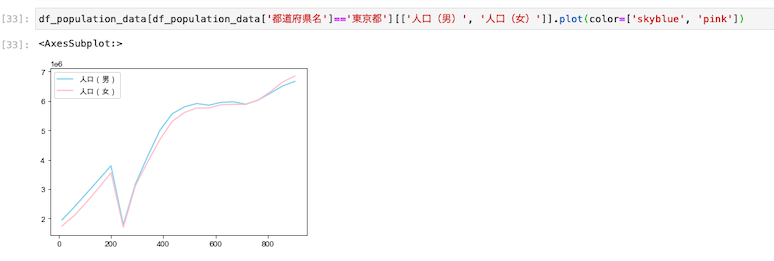
折れ線グラフで東京都の男女ごとの人口推移を表示させる
| df_population_data[df_population_data[‘都道府県名’]==’東京都’][[‘人口(男)’, ‘人口(女)’]].plot(color=[‘skyblue’, ‘pink’]) |
グラフかするにあたり、抽出したい項目には東京都を指定し、年代ごとの男女ごとの人口推移を可視化するコードを記述した。
棒グラフで東京都の男女ごとの人口推移を表示させる
| df_population_data[df_population_data[‘都道府県名’]==’東京都’][[‘人口(男)’, ‘人口(女)’]].plot(kind=’bar’, color=[‘skyblue’, ‘pink’]) |
折れ線グラフと異なるのは、kind=’bar’という表記の有無。
この表記があると、棒グラフになる、ということだと思う。
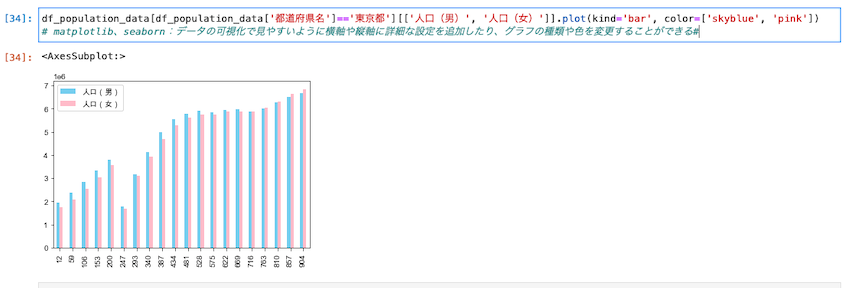
折れ線グラフと棒グラフの両方をうまく表示させることができた。
まずはこの今回のコード等を別のcsvデータでも試して同じような動作をするかどうかを確認していけるようにする。
補足
この項はプログラミング言語PythonのライブラリであるPandasの学習復習用に整理したものである。
YouTubeチャンネル/キノコードさんが解説する動画を視聴し、あとで自分で見直しながらコードを書いていけるように内容をまとめたもの。
まとめを見ても分からないものについては、再度動画視聴を行う。

