 Solo-Yase
Solo-Yase 

目次
当記事について
Python学習を独学でいろいろ手を出してきた結果、YouTube学習に落ち着きました。
記事という体裁をとっていますが、動画視聴後の復習での振り返り用として主に自分に向けて記事を書いています。
YouTube学習を始めた経緯
YouTubeでは数多のプログラマーの方々が非常に有益な情報を発信してくれています。
そんな多くのチャンネルの中からキノコードさんに辿り着いたのは偶然でした。
動画の解説が自分にとっては分かりやすく、初学者に向けて作成してくれている点も視聴開始のきっかけとなりました。
そのため、YouTube学習はキノコードさんのチャンネルに絞って学習しています。
Youtube:キノコード/プログラミング学習チャンネル
データの集計について
今回はPythonを使ったデータ集計について学習する。
Excel:
- sum関数:合計を算出する
- sumifs関数:複数の条件を指定して数値を合計する
- countif関数:指定した条件に合うデータを検索し、検索したデータに一致するセルの個数を求める
SQL:
- groupby:指定したカラムの値をキーとしてグループ化することができる機能で、集約関数を用いることでグループごとに数値などの値を集計することができる
Pythonでは集計方法をカスタマイズすることができるため、独自の集計なども行うことができる。
また、ExcelやSQLではできない集計方法も可能である。
今回使用するExcelデータ
今回使用するデータは、売上データに欠損値があるExcelデータを使用する。
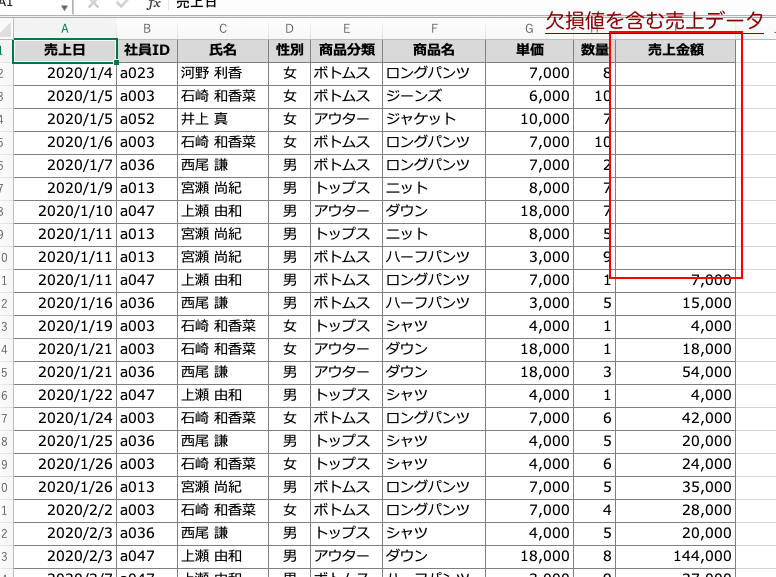
上記の通り、売上金額に欠損値がある。
データの読み込み
| import pandas as pd pd.options.display.max_rows = 10 pd.options.display.max_columns = None |
上記のように記述。
- 表示する行数を10行
- 表示する列数を無制限
以上のように表示オプションを設定。
| df = pd.read_excel( ‘ sample.xlsx ‘ , sheet_name = ‘ 実績管理表_売上欠損 ‘ ) df |
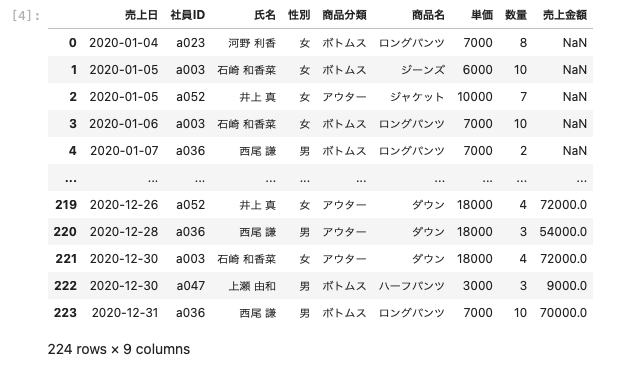
Excelファイルと同様に欠損値のあるデータを読み込むことができた
groupbyを使って氏名ごとに集計する
| df.groupby( ‘ 氏名 ‘ ) |

このようにgroupbyだけを記述したコードでは、コード自体がオブジェクト化されただけとなり、集計結果が表示されない。
平均を算出する
| df.groupby ( ‘ 氏名 ‘ ) . mean( ) |
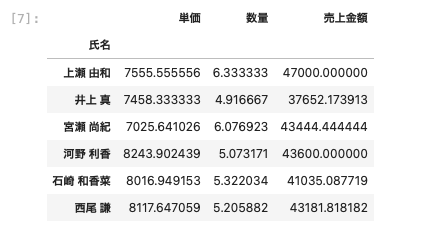
上記のようにmean( )を付け加えることで氏名ごとに単価・数量・売上金額の平均値が算出された。
売上金額だけを平均値として算出したい場合
上記のコードでは、単価・数量・売上金額の3つの平均値が表示されたが、売上金額だけの平均値を算出する場合には次のように記述すれば良い
| df [ [ ‘ 氏名 ‘ , ‘ 売上金額 ‘ ] ] . groupby ( ‘ 氏名 ‘ ) . mean ( ) |
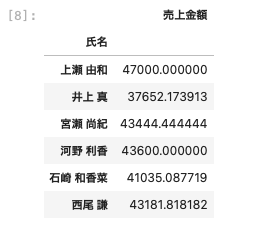
氏名ごとの売上金額の平均値を算出することができた
小数点以下をまるめる表示に設定を変更する
上記の平均値は小数点以下も数字が並んでおり、ぱっと見で見づらくなってしまっている。
そのため、小数点以下を表示しないように設定を変更する。
| pd.options.display.float_format = ‘ { : . 0 f } ‘ . format |
また、この記述はoptionsなので、冒頭で設定した表示列数や表示行数の設定と同じ形式となる。
上記コードを記述した上であらためて平均値を求めるコードを記述する
| df [ [ ‘ 氏名 ‘ , ‘ 売上金額 ‘ ] ] . groupby ( ‘ 氏名 ‘ ) . mean ( ) |
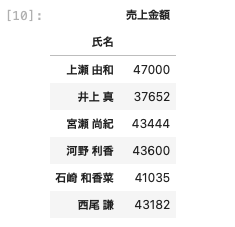
このようにぱっと見でデータが見やすくなった。
小数点以下の記述方法を設定する関数で、『 ‘ { : . 0 f } ‘』のように記述することで小数点以下を省略することができる。
ちなみに小数点第2位まで表示させたい場合には、 { : . 2 f } のように0の部分を2に変更してあげれば良い。
また、小数点第4位までの表示であれば、 { : . 4 f } のような記述となる。現時点ではこう書けばいいんだなーくらいの認識でOK
氏名ごとに売上金額の合計を算出する
氏名ごとに売上金額を表示するのではなく、売上金額の合計値を算出したい場合には、次のように記述をする
| df [ [ ‘ 氏名 ‘ , ‘ 売上金額 ‘ ] ] . groupby ( ‘ 氏名 ‘ ) .sum ( ) |
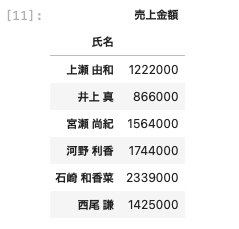
氏名ごとに売上金額のデータの個数を算出する
売上金額のデータがいくつあるのかといったように、データの個数を計算するには、次のように記述する。
| df [ [ ‘ 氏名 ‘ , ‘ 売上金額 ‘ ] ] . groupby ( ‘ 氏名 ‘ ) . count ( ) |

指定したデータの個数を算出してくれるが、欠損値がある場合には除外されるので注意が必要
欠損値がある場合も除外せずにデータの個数を算出するには
欠損値がある場合にも除外せずにデータの個数を算出するには、size( )を使用する。
| df [ [ ‘ 氏名 ‘ , ‘ 売上金額 ‘ ] ] . groupby ( ‘ 氏名 ‘ ) . size ( ) |

売上金額データのN番目のデータを取得する
氏名ごとに売上金額を計算したデータのN番目のデータの一覧を表示させたい場合には次のように記述する。(今回は5番目のデータとして記述)
| df [ [ ‘ 氏名 ‘ , ‘ 売上金額 ‘ ] ] . groupby ( ‘ 氏名 ‘ ) . nth ( 5 ) |
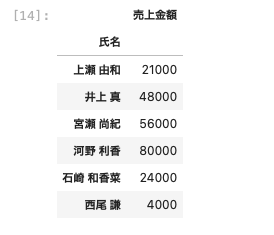
このように5番目のデータのみを抽出することができた。
A番目のデータを取得することができる。
このメソッドではカウントは0からはじまるため、仮にnth(5)と記述した場合には、実質6番目が算出されることになるので注意が必要である
nthメソッドを使った際に、該当値が欠損値だった場合
上記のデータのように氏名ごとの0番目のデータがすべて欠損値となっている。
この欠損値を指定して記述した場合はどのような結果が出るか。
| df [ [ ‘ 氏名 ‘ , ‘ 売上金額 ‘ ] ] . groupby ( ‘ 氏名 ‘ ) . nth ( 0 ) |

以上のように該当の数値が欠損値だった場合にはNaNが表示された
氏名ごとに集計したデータのそれぞれの最大値を取得する
次に、氏名ごとに売上金額のデータを取得しつつ、その売上金額の最大値がいくつなのかを取得したい場合には、次のように記述する
| df [ [ ‘ 氏名 ‘ , ‘ 売上金額 ‘ ] ] . groupby ( ‘ 氏名 ‘ ) . max ( ) |
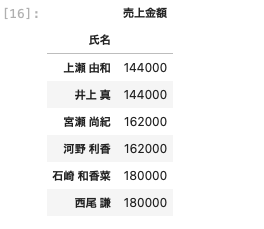
上記のように、氏名ごとの売上金額の最大値が表示された
氏名ごとに集計したデータの最小値を取得する
上記と同様に今度は売上金額の最小値を算出してみる
| df [ [ ‘ 氏名 ‘ , ‘ 売上金額 ‘ ] ] . groupby ( ‘ 氏名 ‘ ) . min ( ) |
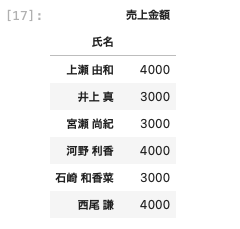
上記の通り、売上金額の最小値を取得することができた
氏名ごとに集計したデータの中央値を算出する
次に、売上金額の中央値を算出してみる
| df [ [ ‘ 氏名 ‘ , ‘ 売上金額 ‘ ] ] . groupby ( ‘ 氏名 ‘ ) . median ( ) |
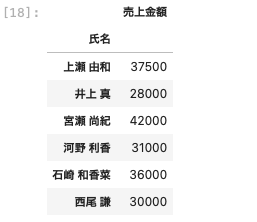
ここで、中央値と平均値のざっくりとした違いについて記述する
- 平均値:全てのデータを足し合わせて、データの個数で割った値のこと
- 中央値:データを降順(または昇順)で並べたときに、ちょうど真ん中にくる値のこと
データが均等に分布していれば中央値と平均値が同じになることもある
氏名ごとに集計したデータの標準偏差を算出する
| df [ [ ‘ 氏名 ‘ , ‘ 売上金額 ‘ ] ] . groupby ( ‘ 氏名 ‘ ) . std ( ) |
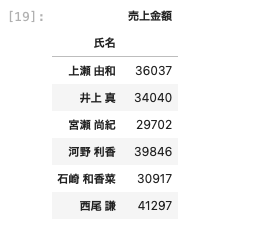
このように標準偏差も算出することができたが、この標準偏差がどんなものかについては正直良く分かっていない。
おそらく統計などで使うデータなのだと思うが、ここでは記述だけに留めておく
氏名ごとに集計したデータの分散値を算出する
上記と同様に統計で使いそうな分散値。
ここでは記述方法だけを表示する。
| df [ [ ‘ 氏名 ‘ , ‘ 売上金額 ‘ ] ] . groupby ( ‘ 氏名 ‘ ) . var ( ) |
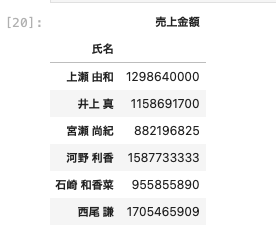
複数の要素を集計する方法
氏名と商品分類ごとに売上金額の平均を算出する
氏名と商品分類ごとにデータを集計し、売上金額の平均値をもとめるには次のように記述する
| df [ [ ‘ 氏名 ‘ , ‘ 商品分類 ‘ , ‘ 売上金額 ‘ ] ] . groupby ( [ ‘ 氏名 ‘ , ‘ 商品分類 ‘ ] ) . mean( ) |

このように氏名と商品分類がインデックスとなり、売上金額の平均値が算出された
集計する要素をインデックスに指定せずに算出する方法
上記コードでは氏名と商品分類がインデックスとなってデータが算出された。
次に氏名と商品分類をインデックスに指定せずにデータを算出するには、次のように記述してあげれば良い。
| df [ [ ‘ 氏名 ‘ , ‘ 商品分類 ‘ , ‘ 売上金額 ‘ ] ] . groupby ( [ ‘ 氏名 ‘ , ‘ 商品分類 ‘ ] , as_index = False ) . mean ( ) |

上記のように氏名と商品分類がインデックスとならずにデータを算出することができた。
別の記述方法で平均値を算出する方法
aggメソッドを使って平均を算出する
| df [ [ ‘ 氏名 ‘ , ‘ 売上金額 ‘ ] ] . groupby ( [ ‘ 氏名 ‘ ] ) . mean ( ) |
| df [ [ ‘ 氏名 ‘ , ‘ 売上金額 ‘ ] ] . groupby ( [ ‘ 氏名 ‘ ] ) . agg ( ‘ mean ‘ ) |
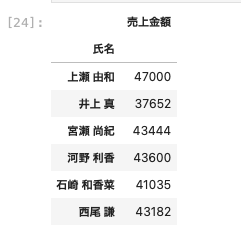
一度に複数の処理を適用することができるので非常に便利
aggメソッドを使って、氏名ごとに平均値と合計を取得する
| df [ [ ‘ 氏名 ‘ , ‘ 売上金額 ‘ ] ] . groupby ( [ ‘ 氏名 ‘ ] ) . agg ( [ ‘ mean ‘ , ‘ sum ‘ ] ) |
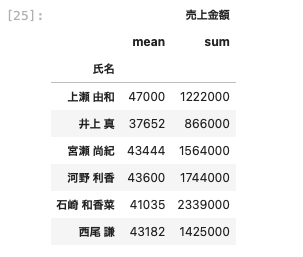
氏名ごとに平均と合計を算出し、3桁区切りで表示する方法
表示する桁数が多ければ多いほどぱっと見たときに数字の桁が分からないことがある。
そのため、桁を区切るように表示を変更することもできる。
| df_group = df [ [ ‘ 氏名 ‘ , ‘ 売上金額 ‘ ] ] . groupby( [ ‘ 氏名 ‘ ] ). agg ( [ ‘ mean ‘, ‘ sum ‘ ] ) df_group . applymap ( ‘ { : , . 0 f } ‘ . format ) |
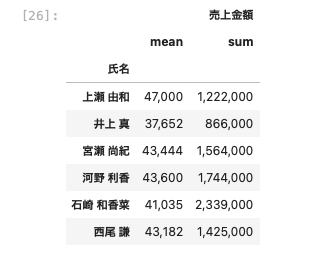
このように桁を区切って表示することでぐっと見やすくなった。
applymap( ‘ { : , . 0 f } ‘ . format )
とりあえず現時点では3桁区切りで記述する際には上記のように記述すれば良いとだけ覚えておく
aggメソッドを使用して、平均・合計・個数・最大値・最小値・標準偏差・分散値を3桁区切りのデータでまとめて一度に表示させる方法
前述の通り、aggメソッドは複数の処理をまとめて適用することができるため非常に便利である。
そこで今回は平均・合計・個数・最大値・最小値・標準偏差・分散値の7項目を一度に表示させるコードを記述する。
| df_group = df [ [ ‘ 氏名 ‘ , ‘ 売上金額 ‘ ] ] . groupby ( [ ‘ 氏名 ‘ ] ) . agg ( [ ‘ mean ‘ , ‘ sum ‘ , ‘ count ‘ , ‘ max ‘ , ‘ min ‘ , ‘ std ‘ , ‘ var ‘ ] ) df_group . applymap ( ‘ { : , . 0 f } ‘ . format ) |
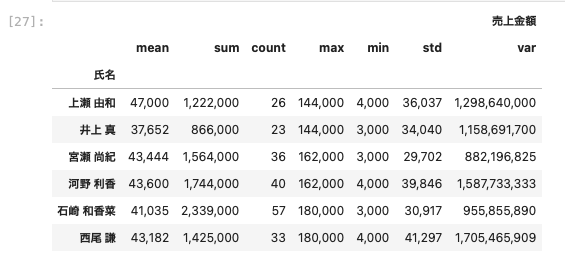
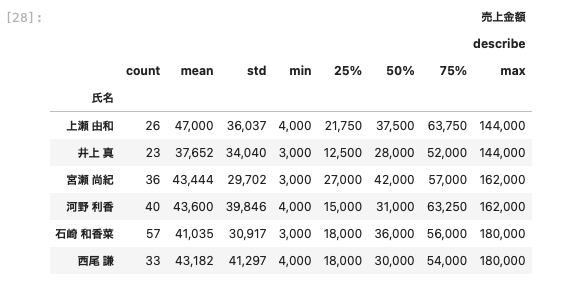
describeメソッドでグループごとの統計量を3桁区切りで算出する
aggメソッドを用いて算出したデータに似ているものとしてdescribeメソッドがある。
こちらのメソッドを使ってデータを算出してみる。
| df_group = df [ [ ‘ 氏名 ‘ ,’ 売上金額 ‘ ] ] .groupby ( ‘ 氏名 ‘ ) .agg ( [ ‘ describe ‘ ] ) df_group . applymap ( ‘ { : , . 0 f } ‘ . format ) |
自作の関数を適用することも可能
defで自作関数を定義する
まずnumpyをインポートし、defで自作の関数を定義する。
ここでは消費税(10%)込みの合計金額を計算する関数を定義する。
| import numpy as np def cal_tax ( s ) : return np . sum ( s ) * 1.10 df_group = df [ [ ‘ 氏名 ‘ , ‘ 売上金額 ‘ ] ] . groupby ( ‘ 氏名 ‘ ) . agg ( { ‘ 売上金額 ‘ : cal_tax } ) df_group . applymap ( ‘ { : , . 0 f } ‘ . format ) |
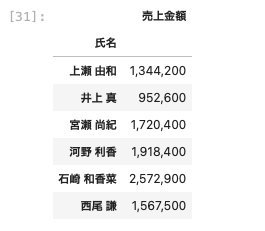
以上のように自作関数を使ってデータの算出も可能である。
自作関数については、まだ学習途中なので、今後理解が深まった段階であらためて使用していきたいと思う。
まとめ
今回は、いろいろなデータ集計について学習することができた。
実際にコードを記述した際にどのような結果が出るのかを確認しながら進めることができたのでかなり理解は深まったように思う。
今回使用したものについては仕事でも使う機会がありそうなものばかりだったので、しっかりと覚えて少しずつ使っていけるようにしたい。

