 Solo-Yase
Solo-Yase 

目次
当記事について
Python学習を独学でいろいろ手を出してきた結果、YouTube学習に落ち着きました。
記事という体裁をとっていますが、動画視聴後の復習での振り返り用として主に自分に向けて記事を書いています。
YouTube学習を決めた経緯
YouTubeでは数多のプログラマーの方々が非常に有益な情報を発信してくれています。
そんな多くのチャンネルの中からキノコードさんに辿り着いたのは偶然でした。
動画の解説が自分にとっては分かりやすく、初学者に向けて作成してくれている点も視聴開始のきっかけとなりました。
そのため、YouTube学習はキノコードさんのチャンネルに絞って学習しています。
Youtube:キノコード/プログラミング学習チャンネル
csv・Excelファイルの読み込み、書き出し
前提
csvファイル、Excelファイル、データベースからのデータの読み込み、書き出し、データ集計や加工などの前処理を効率化することができる
| import pandas as pd pd.set_option( ‘ display . max_rows ‘ , 10 ) |
データフレームの全ての行を表示すると、読み込むデータ量によっては画面が見づらくなるので、表示する行数をあらかじめ設定することができる。
オプションの設定を確認・変更することができる関数
全ての行を表示させるには、Noneに設定する(–max_rows’ , None)
表示行数を指定することができるメソッドには、
- head()
- tail()
もある。
この項で使用するデータ:政府が発表している1920年〜2015年までの全国の人口推移データを使う
csvファイルを読み込む
| df_csv = pd.read_csv( ‘ data.csv ‘ , encoding = ‘ shift-jis ‘ ) df_csv |
カラム名を指定してデータを読み取る
| df_csv = pd.read_csv ( ‘ data01.csv ‘ , encoding=’shift-jis ‘ , names = [ ‘ area_code ‘ , ‘ area ‘ , ‘ GG ‘ , ‘ gg ‘ , ‘ yyy ‘ , ‘ population ‘ , ‘ man ‘ , ‘ woman ‘ ] ) |
インデックスを指定してデータを読み取る
上記データの都道府県名をインデックスに指定する。
都道府県名の項は列番号が1となる。(都道府県コードが0)
| df_csv = pd.read_csv( ‘ data.csv ‘ , encoding = ‘ shift-jis ‘ , index_col = 1 ) df_csv |
複数のインデックスを指定して読み取る方法
| df_csv = pd.read_csv ( ‘ data.csv ‘ , encoding = ‘ shift-jis ‘ , index_col = [ 0, 1, 2, 3, 4 ] ) df_csv . head( ) |
インデックスが1つのときと複数のときのデータ型を確認する
インデックスが1つの場合
| type ( df_csv . index ) |
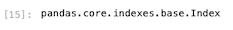
データ部分のデータ型についても確認する
| df_csv . dtypes |

type関数:データ型を確認するときに使う
dtype関数:データ部分のデータ型を確認するときに使う
インデックスを複数にした場合
| type ( df_csv . index ) |

インデックスが1つのときとは異なり、MultiIndexと表示が変わった。
複数の列をインデックスとしたときのインデックスのタイプをあらわす
データ部分のデータ型についても確認してみる
| df_csv . dtypes |

このようにインデックスが1つか複数であるかによって、インデックスのデータ型やデータ部分のデータ型が変わることがわかった。
データを書き出す方法
csvファイルとして書き出す
| df_csv.to_csv( ‘ data_csv.csv ‘ , encoding = ‘ shift-jis ‘ ) |
保存先にしていしたファイルに書き出されているかを確認する
csvファイルに書き出す
Excelファイルを読み込む
まずdata.xlsxのエクセルファイルの中身を確認しておくと、こちら。
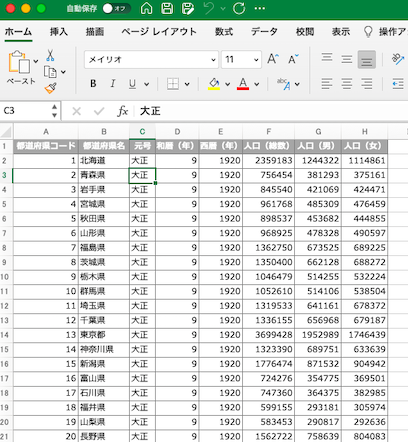
| pd.read_excel ( ‘ data.xlsx ‘ ) |
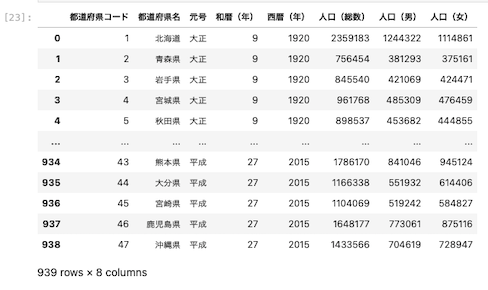
Excelファイルを読み込む
- 読み込みを始める行を指定する
- カラムに指定する列を指定する
- カラム名を指定して読み込む
といったように使い方が非常に似ている
先頭の2行が空白になっているデータを読み込んだ際の挙動について
最初の2行が空白になっているデータを読み込む
先ず読み込むデータはこちら。
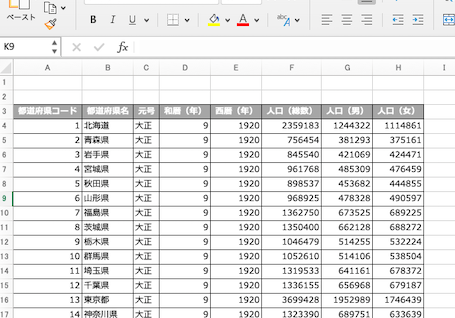
上図のとおり、先頭の2行が空白になっている。
このデータを読み込んでみる。
| pd.read_excel ( ‘ data01 . xlsx ‘ ) |
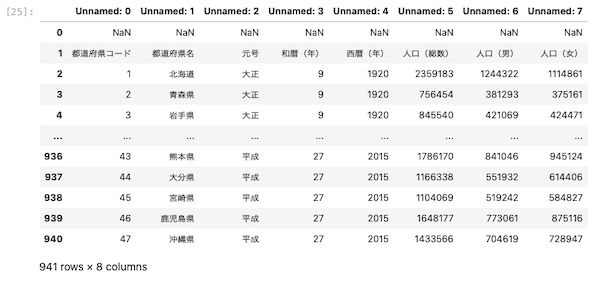
上図のとおり先頭2行が空白のデータを読み込むと、
- 1行目:Unnamed:が表示
- 2行目:NaN:が表示
空白の行にUnnamedとNaNという表示が加えられた。
空白になっている最初の2行をスキップしてデータを読み込む
先頭の2行は特に必要がないので、この2行分をスキップし、3行目からデータを読み込んでみる。
| pd . read_excel ( ‘ data01.xlsx ‘ , skiprows = 2 ) |
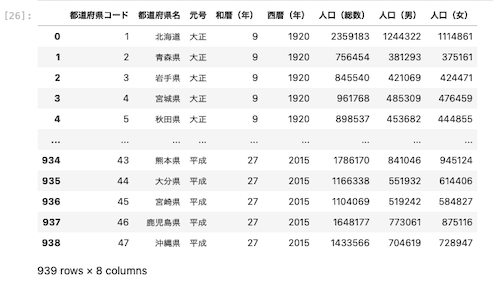
スキップする行数Aを指定することができる。(この場合は2行スキップするという意味)
カラム名を指定してExcelファイルを読み込む
| pd.read_excel ( ‘ data01.xlsx ‘ , skiprows = 2 , header = [ 0 ] ) |
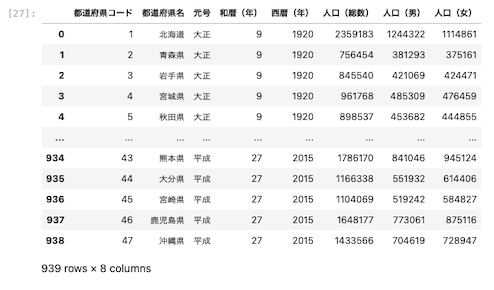
カラムに指定したい行番号Aを指定する
行番号の1行目をカラム名に指定する場合は、「header = [ 0 ]」と記述をしてもしなくても同じ。仮に2行目以降をカラム名に指定したい場合には記述が必要となる。
header = [ 1 ] として見た場合にどうなるかを確認する
2行目をカラム名として指定する場合には「header = [ 1 ] 」と記述することになるが、この場合はどうなるかを実際に確認してみる。
| pd.read_excel ( ‘ data01.xlsx ‘ , skiprows = 2 , header = [ 1 ] ) |
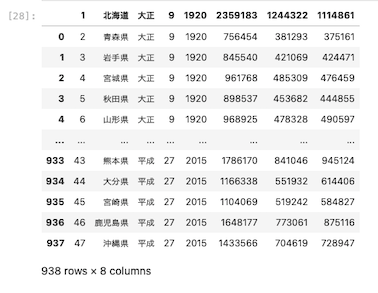
ヘッダーがないデータを読み込む
都道府県コードや都道府県名、元号、和暦などのヘッダーがついていないデータを読み込む場合はどうなるのか。
まずは読み込むExcelファイルの中身を確認する。
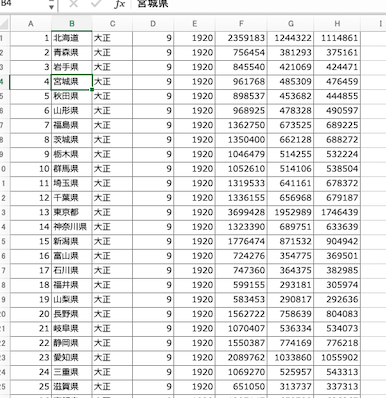
このヘッダーがついていないファイルを読み込みつつ、連番を割り振るコードを記述する。
| pd.read_excel ( ‘ data02.xlsx ‘ , header = None) |
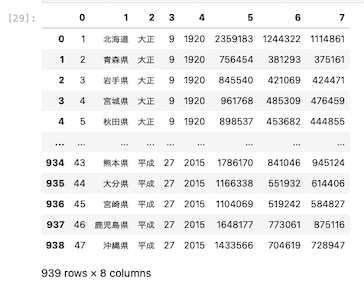
header = None と記述すると、ヘッダーは自動的に連番が割り当てられる
1行目と2行目をカラム名に指定する方法
次に、1行目には地域名、2行目には各列に名前が付されているものをカラム名に指定するにはどうすれば良いか。
まず、読み込む元のデータを確認する。
| pd.read_excel ( ‘ data03.xlsx ‘ , header = [ 0 , 1 ] ) |

上図のとおり、1行目と2行目をカラム名に指定することができた
インデックスを指定してExcelファイルを読み込む
インデックスを指定してファイルを読み込む方法
まず、読み込むデータを確認する。
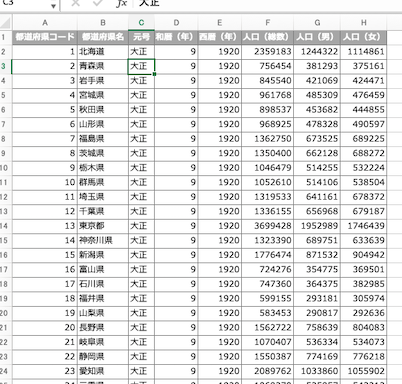
上図の「都道府県コード」がインデックス名になるようにコードを記述していく
| pd.read_excel ( ‘ data.xlsx ‘ , index_col = 0 ) |
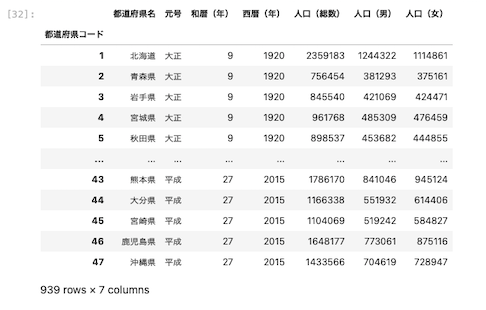
上図のとおり、都道府県コードがインデックス名に指定して読み込むことができた。
このコードは番号を指定してインデックス名を指定したが、次のように記述することもできる。
| pd.read_excel ( ‘ data.xlsx ‘ , index_col = ‘ 都道府県コード ‘ ) |
都道府県コードを直接記述した場合も同じようにインデックス名を指定することができた。
行のスキップとインデックス名を指定してファイルを読み込む
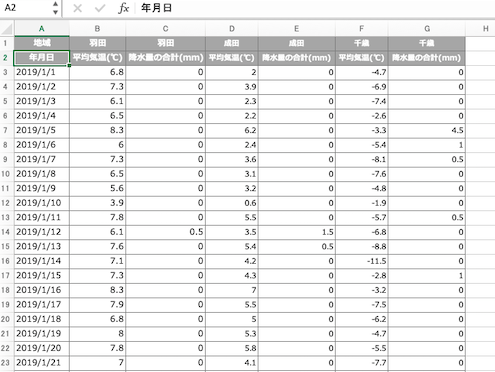
読み込むデータの1行目をスキップし、年月日をインデックスに指定してデータを読み込む
まずは、読み込む元になるデータを確認する。
| df_excel = pd.read_excel ( ‘ data03.xlsx ‘ ) df_excel |
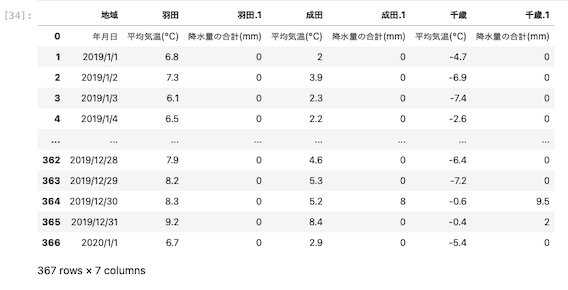
このデータの1行目をスキップし、平均気温や降水量がカラム名になるように指定する。
また、年月日がインデックスになるように指定するコードを記述する。
| df_excel = pd.read_excel( ‘ data03.xlsx ‘ , skiprows = 1, index_col = ‘ 年月日’ ) df_excel |
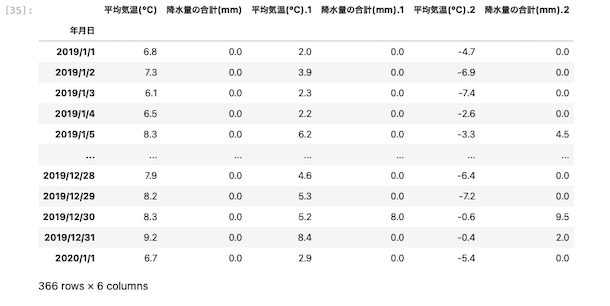
上図のとおり、カラム名とインデックス名を指定してファイルを読み込むことができた。
インデックスのデータ型を確認する
| type ( df_excel . index ) |

通常のインデックスとなっていることが確認できた
indexで指定した列を日付型で読み込む
インデックス名で指定した列を日付型として読み込む方法
| df_excel = pd.read_excel ( ‘ data03.xlsx ‘ , skiprows = 1, index_col = ‘ 年月日 ‘ , parse_dates = True ) df_excel |
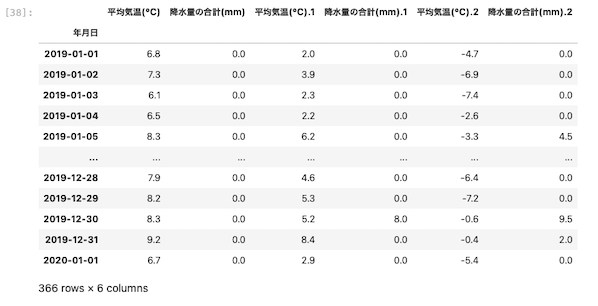
パッと見日付型として読み込みができたのか不安になるが、
2019/01/01 ⇨ 2019ー01ー01
以上のように変化していることがわかる。
念のため、日付型で読み込んだデータのデータ型を確認する
| type ( df_excel . index ) |

通常のindexからDatetimeIndexに変更されていることがわかった。
このように記述することで、インデックスで指定された列が日付型として読み込むことができる
インデックス名が日付型になると、特殊な集計が可能となり、利便性が向上する
エクセルファイルとして書き出す方法
| df_excel.to_excel ( ‘ df_excel.xlsx ‘ ) |
上図のとおり、df_excel.xlsxとして書き出すことができた。
クリップボードのデータを書き込む方法
コピーしたデータをそのままデータフレームとして使う
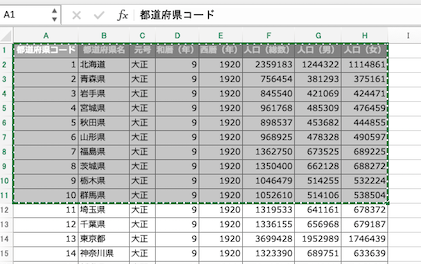
上図のようにファイル上の必要な範囲を指定してコピーをする。
そのコピーしたデータをデータフレームとして読み込むことができる。
| df_cb = pd.read_clipboard( ) df_cb |
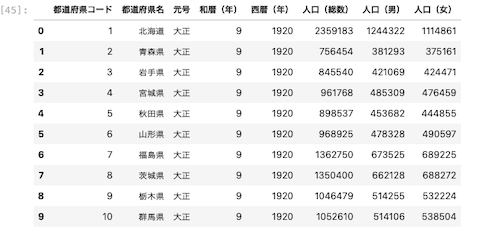
上図のように、エクセルファイル上で範囲を指定してコピーした部分だけをデータフレームとして読み込むことができた。
まとめ
今回は、データの読み込みと書き出しについて勉強した。
前回のデータフレームとシリーズの項とは異なり、実際のデータを使って実践することができた分、理解は深まったような気がする。
また、日付を日付型として読み込むコードの記述方法も出てきたので、前回自分の体調管理表でつまづいたコードがうまく書けるようになるかもしれない。
補足
この項はプログラミング言語PythonのライブラリであるPandasの学習復習用に整理したものである。
YouTubeチャンネル/キノコードさんが解説する動画を視聴し、あとで自分で見直しながらコードを書いていけるように内容をまとめたものである。

