 Solo-Yase
Solo-Yase 

目次
当記事について
Python学習を独学でいろいろ手を出してきた結果、YouTube学習に落ち着きました。
記事という体裁をとっていますが、動画視聴後の復習での振り返り用として主に自分に向けて記事を書いています。
YouTube学習を始めた経緯
YouTubeでは数多のプログラマーの方々が非常に有益な情報を発信してくれています。
そんな多くのチャンネルの中からキノコードさんに辿り着いたのは偶然でした。
動画の解説が自分にとっては分かりやすく、初学者に向けて作成してくれている点も視聴開始のきっかけとなりました。
そのため、YouTube学習はキノコードさんのチャンネルに絞って学習しています。
Youtube:キノコード/プログラミング学習チャンネル
mergeメソッド
mergeメソッドとは
データフレームの結合方法のひとつ。
結合とは2つのデータフレームをくっつけること。
mergeメソッドは、SQLのjoinやExcelのVlookupと似ている
データフレームを作成する
まずは2つのデータフレーム(df01とdf02)を作成する。
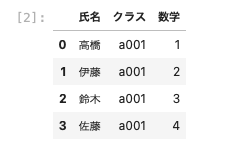
- 変数df01:カラム名「氏名・クラス・数学」のデータフレームを代入
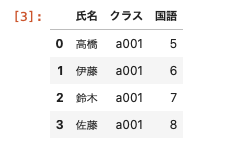
- 変数df02:カラム名「氏名・クラス・国語」のデータフレームを代入
それぞれ「氏名」と「クラス」が同じキーで、『数学』と『国語』はそれぞれ片方にしかないキーとなる。
| import pandas as pd df01 = pd.DataFrame( { ‘ 氏名 ‘ : [ ‘ 高橋 ‘ , ‘ 伊藤 ‘ , ‘ 鈴木 ‘ , ‘ 佐藤 ‘ ] , ‘ クラス ‘ : [ ‘ a001 ‘ , ‘ a001 ‘ , ‘ a001 ‘ , ‘ a001 ‘ ] , ‘ 数学 ‘ : [ 1 , 2 , 3 , 4 ] } ) df01 df02 = pd.DataFrame( { ‘ 氏名 ‘ : [ ‘ 高橋 ‘ , ‘ 伊藤 ‘ , ‘ 鈴木 ‘ , ‘ 佐藤 ‘ ] , ‘ クラス ‘ : [ ‘ a001 ‘ , ‘ a001 ‘ , ‘ a001 ‘ , ‘ a001 ‘ ] , ‘ 国語 ‘ : [ 5 , 6 , 7 , 8 ] } ) df02 |
同じ名前のカラムをキーに結合する
次のように記述することで2つのデータフレームを、指定したキーで結合することができる。
| pd.merge ( df01 , df02 , on = ‘ 氏名 ‘ ) |

merge ( ‘ 第一引数 ‘ , ‘ 第二引数 ‘ , on = ‘ 結合させるキーとなるカラム名 ‘ )
上記のように記述することで第一引数と第二引数を結合させるキーで結合することができる
重複するカラム名を指定して接尾辞を変更する方法
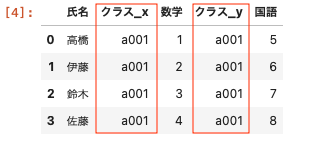
上記で結合した2つのデータフレームはクラス名も重複しており、クラス_x、クラス_yと名前の後ろに文字列がついている。
この重複しているカラムの接尾辞を変更する。
| pd.merge (df01 , df02 , on = ‘ 氏名 ‘ , suffixes = [ ‘ _left ‘ , ‘ _right ‘ ] ) |
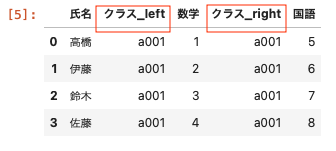
カラム名の接尾辞を指定することで名前を変更できる
今回は(クラス_left、クラス_right)となっている。
結合で重複するカラムの片方だけ接尾辞を変更する場合
上記のように重複したカラムにそれぞれleft、rightの接尾辞をつけて名前を変更しているが、これをカラムの左はそのままで、右のカラム名のみ「_重複」と名前を変更するには次のように記述する。
| pd.merge ( df01 , df02 , on = ‘ 氏名 ‘ , suffixes = [ ‘ ‘ , ‘_重複 ‘ ] ) |
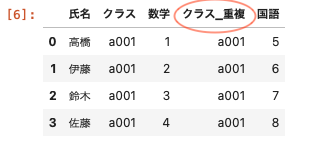
suffixes = [ ‘ ‘ , ‘ _重複 ‘ ] :左のように空で渡すことで『変更なし』となる
異なるカラム名をキーに結合する方法
「氏名」を『名前』に変更してあるデータフレームであるdf02_nameを新たに作成する。
| df02_name = pd.DataFrame ( { ‘ 名前 ‘ : [ ‘ 高橋 ‘ , ‘ 伊藤 ‘ , ‘ 鈴木 ‘ , ‘ 佐藤 ‘ ] , ‘ クラス ‘ : [ ‘ a001 ‘ , ‘ a001 ‘ , ‘ a001 ‘ , ‘ a001 ‘ ] , ‘ 国語 ‘ : [ 5 , 6 , 7 , 8 ] } ) df02_name |

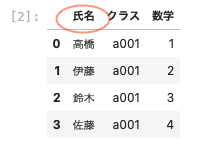

氏名と名前をキーにデータフレームを結合する
上記のように氏名と名前と異なるキーでデータフレームを結合する。
| pd.merge ( df01 , df02_name , left_on = ‘ 氏名 ‘ , right_on = ‘ 名前 ‘ ) |
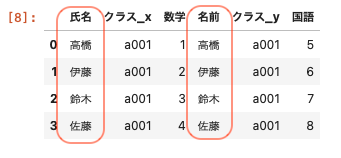
上記のとおり、異なるキー同士で結合することができた
一意とは
一意とは?
一意とは、キーがすべての値が重複しないことの意。
たとえば、
- 1、2、3、4、5は一意
- A、B、C、D、Eは一意
逆に
- 1、1、2、2、3、3は一意ではない
- A、A、B、B、C、Cは一意ではない
一意=ユニークとも呼ばれる
2つのカラムがセットで一意になる場合
a001のクラスに高橋さんがいて、a002のクラスにも高橋さんがいる。
この高橋さんの名前だけ見た場合、名前が重複しているので一意であるとは言えない。
しかし、a001クラスの高橋さん、a002クラスの高橋さんと言ったように2つのカラムとセットで見てみると、それぞれ別の高橋さんということになり、これは一意であると言える。
このように、2つのカラムをキーに結合する場合をみていく
df03に名前とクラスがセットで一意となるデータフレームを作成する
| df03 = pd.DataFrame ( { ‘ 名前 ‘ : [ ‘ 高橋 ‘ , ‘ 高橋 ‘ ] , ’ クラス ‘ : [ ‘ a001 ‘ , ‘ a002 ‘ ] , ’ 英語 ‘ : [ 15, 16 ] } ) df03 |

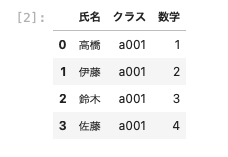
上記のようにdf01とdf03のような2つのデータフレームを準備した。
それぞれのデータフレームはキーが「氏名」と「名前」で異なっているもののa001の高橋という2つのキーで結合してみる。


| pd.merge ( df01, df03, left_on = [ ‘ 氏名 ‘ , ‘ クラス ‘ ] , right_on = [ ‘ 名前 ‘ , ‘ クラス ‘ ] ) |

結合の種類(inner、outer、left、rightの4種)
4つの結合方法
innerとは
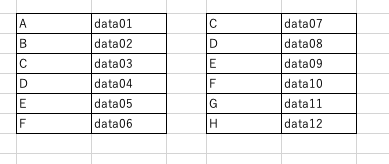
innerでは2つのデータフレームで共通しているキーのみを結合する方法となる。
上記の2つのデータフレームを例にすると、2つのデータフレームで共通しているキーというのは次のようになります。
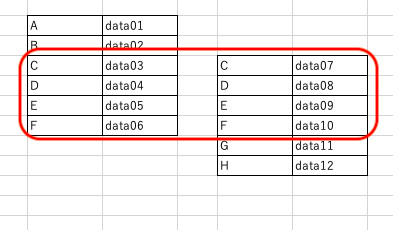
以上のように赤線で囲った部分が共通しているキーとなり、結合される部分でもある。
leftとは
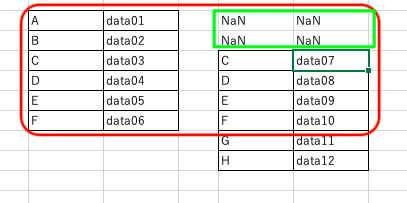
結合のleftを使用した場合には、左のデータフレームはそのままに、右のデータフレームは、共通する部分だけが残り、存在しない値にはNaNが表示される。
rightとは
leftとは別に右のデータフレームはそのままに左のデータフレームは共通する部分だけが残り、存在しない値にはNaNが表示される。
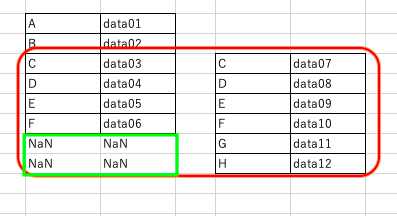
outerとは

outerは上記のように、左と右それぞれに共通する部分についてはそのまま結合し、それ以外の片方だけにしかないものについては、欠損値のNaNが表示されてそのまま残す結合方法となります。
- inner:共通しているキーのみを結合する方法
- left:左のデータフレームをベースに結合する方法
- right:右のデータフレームをベースに結合する方法
- outer:共通するものだけ結合し、それ以外はそのまま残す方法
どういう形で結合させたいのかを考えながら、どのメソッドを使えば実現できるのかを考えよう。
それでは以下から実際にコードを記述しながら結合についてみていくことにする
実際に結合させてみる:left_join
df01に結合させるもうひとつのデータフレームを作成する。
| df04 = pd.DataFrame ( { ‘ 氏名 ‘ : [ ‘ 高橋 ‘ , ‘ 伊藤 ‘ , ‘ 渡辺 ‘ , ‘ 加藤 ‘ ] , ‘ クラス ‘ : [ ‘ a001 ‘ , ‘ a001 ‘ , ‘ a001 ‘ , ‘ a001 ‘ ] , ‘ 国語 ‘ : [ 5 , 6 , 7 , 8 ] } ) df04 |
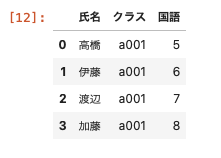
df01のデータフレームにあるデータを残して結合させる
| pd.merge ( df01, df04, on = ‘ 氏名 ‘ , how = ‘ left ‘ ) |
以上のように左のデータフレームがそのまま残り、右のデータフレームは共通する部分がそのまま結合され、欠損箇所はNaNが結合された
right_joinで結合させる
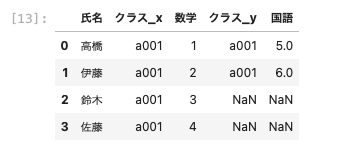
次に、右のデータフレームにあるデータをそのまま残して結合させる。
| pd.merge ( df01, df04, on = ‘ 氏名 ‘ , how = ‘ right ‘ ) |
以上のように、右のデータフレームがそのまま残り、左のデータフレームの共通する部分はそのまま結合、欠損箇所はNaNが表示された
outer_joinで結合させる
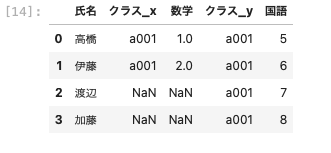
次に両方のデータフレームにあるデータをそのまま全て残してデータを結合させる。
共通する部分はそのままに、欠損箇所はNaNが表示される。
| pd.merge ( df01, df04, on = ‘ 氏名 ‘ , how = ‘ outer ‘ ) |
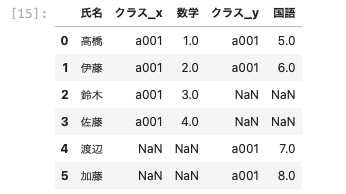
inner_joinで結合させる
次に、両方のデータフレームに共通しているデータ部分だけを残して結合させる。
片方にしかないデータについては除外される。
| pd.merge ( df01, df04, on = ‘ 氏名 ‘ , how = ‘ inner ‘ ) |
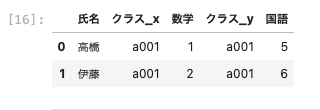
以上のように両方に共通する部分だけが結合され、それ以外は除外された。
joinメソッドはデフォルトでinnerが設定されている
結合メソッドはデフォルトでinnerが設定されているので、結合方法がinnerの場合には結合方法を記述しなくても同様の結果が表示される。
| pd.merge ( df01, df04, on = ‘ 氏名 ‘ ) |
このようにinnerについては記述してもしなくても同様の結果が表示された。
元データの情報を付け加える
2つのデータフレームを結合させたときに、どのデータ部分が表示されているのかを確認するメソッドがある
上記のデータフレームは、outerで2つのデータフレームを結合させたものになる。
このデータフレームを見ただけではどの部分が共通しているのかなどがはっきりとしない場合がある。
そのようなときには、下記のように記述することで元のデータ情報を付け加えることができる。
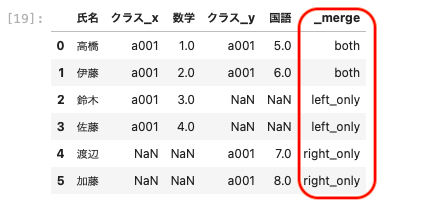
| pd.merge ( df01, df04, on = ‘ 氏名 ‘ , how = ‘ outer ‘, indicator = True ) |
- 両方のデータフレームにあるものはboth
- 左のデータフレームにのみならleft_only
- 右のデータフレームにのみならright_only
以上のように表示させることができる
インデックスをキーに結合する方法
インデックスを指名にしたデータフレームを作成する
| df05 = pd.DataFrame ( { ‘ クラス ‘ : [ ‘ a001’ , ‘ a001 ‘ , ‘ a001 ‘ , ‘ a001 ‘ ] , ‘ 数学 ‘ : [ 1 , 2 , 3 , 4 ] } , index = [ ‘ 高橋 ‘ , ‘ 伊藤 ‘ , ‘ 鈴木 ‘ , ‘ 佐藤 ‘ ] ) df05 |


上記のようにインデックスに名前が指定されているdf05(左)とdf02(右)の2つのデータフレームを使って結合を行う。
インデックスとキーを結合させる
上記のとおり、左はインデックスに名前が指定されたもの、右は名前がキーとして指定されているものになる。
この名前をキーとして結合を行う
| pd.merge ( df05, df02, left_index = True, right_on = ‘ 氏名 ‘ ) |
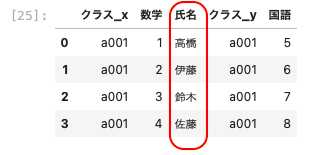
このように名前をキーとして結合することができた。
結合キーでソートして昇順に並び替える
上記の結合したデータフレームの名前を昇順に並べ替えて表示させる。
| pd.merge ( df05 , df02 , left_index = True , right_on = ‘ 氏名 ‘ , sort = True ) |

上記のとおり、キーとなった名前を昇順に並び替えることができた
concatメソッドとの違い
次に学習するのはconcatメソッドになるが、このメソッドはmergeメソッドとそれぞれ状況によって使い分ける必要がある。
- mergeメソッドとは異なりデータを縦方向にも結合することができる
- 3つ以上のデータフレームを結合することができる
- 2つ以上のカラムをキーにすることができない
- 結合方法にinnerやouterはあるが、leftやrightがない
まとめ
今回はデータ同士の結合について学習した。
データの集計のときに感じたような、達成感はあまりなくて、どちらかというと方法論を学習する回だったのかな、と。
データ集計のgroupbyやpivot_tableのように実践的な、仕事でも使うイメージができるものとは違って、「こう書くとこうなるのかー」ということばかりだった。
そのため、それぞれを使う状況があまりイメージできておらずすぐに使いこなせるようになるかは正直微妙なところです。
Pandas入門講座は今回を含めてあと3回なので、前回までに学習した内容も含めて繰り返しコードを写経して身体が覚えるようなところにまで持っていきたい。
