 Solo-Yase
Solo-Yase 

目次
当記事について
Python学習を独学でいろいろ手を出してきた結果、YouTube学習に落ち着きました。
記事という体裁をとっていますが、動画視聴後の復習での振り返り用として主に自分に向けて記事を書いています。
YouTube学習を始めた経緯
YouTubeでは数多のプログラマーの方々が非常に有益な情報を発信してくれています。
そんな多くのチャンネルの中からキノコードさんに辿り着いたのは偶然でした。
動画の解説が自分にとっては分かりやすく、初学者に向けて作成してくれている点も視聴開始のきっかけとなりました。
そのため、YouTube学習はキノコードさんのチャンネルに絞って学習しています。
Youtube:キノコード/プログラミング学習チャンネル
ピボットテーブルとは
ピボットテーブルについて
まずピボットテーブルとは何かというと、2つのカテゴリのデータを同時に集計したものである。
具体例を挙げてみると次のようなものになる。
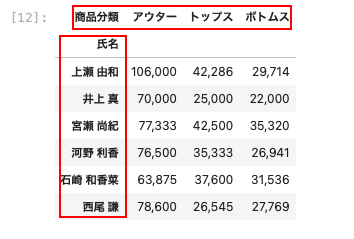
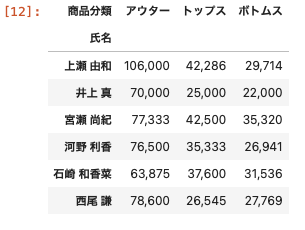
上の表は、売上管理表の氏名と商品分類の2つのカテゴリをベースとして、それぞれの売上の合計を表にしています。
これは氏名と商品分類の2つが軸になっています。
ピボットテーブルという言葉を意味づけすると、ピボットは軸、テーブルは表ということができる。
つまり、氏名や商品分類、商品名などのいろいろなカテゴリを軸にすることで表を作ることができるため、ピボットテーブルと呼ばれている。
ピボットテーブルとは、2つのカテゴリのデータを同時に集計したもの
データの読み込みと表示設定
| import pandas as pd pd.options.display.max_rows = 10 pd.options.display.max_columns = None df = pd.read_excel ( ‘sample.xlsx ‘ , sheet_name = ‘ 実績管理表 ‘ ) df |
まずpandasをインポートする。
オプション設定で表示する行数を10行、表示する列数を無制限に設定する。
sheet_name = ‘ 実績管理表 ‘ と記述することで、シート名を指定してエクセルデータを開くことができる。
ピボットテーブルを使ったデータ集計
氏名ごとに商品を分類してそれぞれの売上金額の合計を算出する
| df_pivot = df.pivot_table ( index = ‘ 氏名 ‘ , columns = ‘ 商品分類 ‘ , values = ‘ 売上金額 ‘ , aggfunc = ‘ sum ‘ ) df_pivot |
pivot_table( )と記述して ( ) 内に軸となるカテゴリを指定する。
aggfuncは集計方法を指定することができる。
- aggfunc = ‘ sum ‘ :合計
- aggfunc = ‘ mean ‘ :平均
- aggfunc = ‘ count ‘ :個数
aggfunc = [ ‘ sum ‘ , ‘ mean ‘ , ‘ count ‘ ]:このように集計方法をリストで渡すことで同時に数種類のデータ集計も行うことができる。
indexのみ指定してgroupbyのような集計をする
| df_pivot = df.pivot_table ( index = ‘ 氏名 ‘ , values = ‘ 売上金額 ‘ , aggfunc = ‘ sum ‘ ) df_pivot |
このようにカラムを指定せずにかくとgroupbyのような表も作成することができる
氏名ごとに商品を分類し、それぞれの売上金額の平均を算出する方法
| df_pivot = df.pivot_table ( index = ‘ 氏名 ‘ , columns = ‘ 商品分類 ‘ , values = ‘ 売上金額 ‘ , aggfunc = ‘ mean ‘ ) df_pivot |
このように氏名ごとに商品が分類されて、それぞれの商品ごとの売上金額の平均を算出することができた。
aggfuncを記述しないと平均値が算出される
aggfuncは集計方法を指定するメソッドだが、このaggfuncを記述しない場合は、自動的にmean(平均値)がデフォルトとして設定される。
念のためaggfuncを記述しない場合どうなるのかをコードを記述して確認してみる
| df_pivot = df.pivot_table ( index = ‘ 氏名 ‘ , columns = ‘ 商品分類 ‘ , values = ‘ 売上金額 ‘ ) df_pivot |
以上のようにmeanを設定した時と同様の結果が出た。
小数点以下をまるめて桁区切りをして数値を見やすくする方法
| df_pivot = df.pivot_table ( index = ‘ 氏名 ‘ , columns = ‘ 商品分類 ‘ , values = ‘ 売上金額 ‘ ) df_pivot.applymap ( ‘ { : , . 0 f } ‘ . format ) |
applymapは前回のgroupbyでも出てきたけれど、現時点ではこのように記述すれば桁区切りで表示できる、とだけ覚えておく。
複数のデータの平均を同時に算出する方法
| df_pivot = df.pivot_table ( index = ‘ 氏名 ‘ , columns = ‘ 商品分類 ‘ , values = [ ‘ 単価 ‘ , ‘ 数量 ‘ , ‘ 売上金額 ‘ ] ) df_pivot.applymap ( ‘ { : , . 0 f } ‘ . format ) |
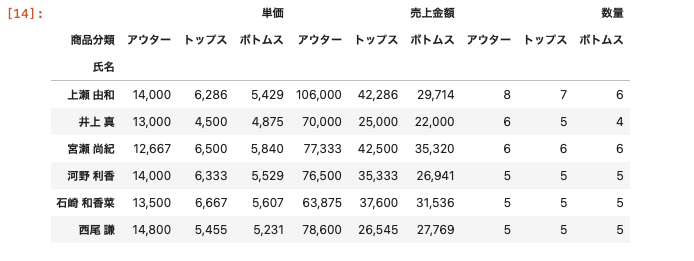
valuesの値をリストで渡すことで、複数のデータの平均値を一度に算出することができる。
aggfuncを記述していないため、デフォルト設定の平均値が算出されている。
複数のインデックスで合計を算出する方法
| df_pivot = df.pivot_table ( index = [ ‘ 氏名 ‘ , ‘ 売上日 ‘ ] , columns = ‘ 商品分類 ‘ , values = ‘ 売上金額 ‘ , aggfunc = ‘ sum ‘ ) df_pivot.applymap ( ‘ { : , . 0 f } ‘ . format) |

上記のようにインデックスの値をリストで渡してあげることで複数のインデックスで合計を算出することができる
欠損値nanの部分を数値の0に置き換える方法
上記の表には数値が当てはまらない部分についてはnanが表示されているが視覚的に見づらくなっているため、当該部分を0に置き換えてみたい。
| df_pivot = df.pivot_table ( index = [ ‘ 氏名 ‘ , ‘ 売上日 ‘ ] , columns = ‘ 商品分類 ‘ , values = ‘ 売上金額 ‘ , aggfunc = ‘ sum ‘ , fill_value = 0 ) df_pivot.applymap ( ‘ { : , . 0 f } ‘ . format ) |

このようにnanが0に置き換わったことでたいぶ見やすくなった。
欠損値をAに置き換える。文字列ではなく数値。
columnsを設定しないときの合計を算出する方法
indexを2つ(氏名と売上日)と、valuesを2つ(売上金額と数量)を設定し、columnsを設定しない場合はどのようになるか。
| df_pivot = df.pivot_table ( index = [ ‘ 氏名 ‘ , ‘ 売上日 ‘ ] , values = [ ‘ 売上金額 ‘ , ‘ 数量 ‘ ] , aggfunc = ‘ sum ‘ ) df_pivot.applymap ( ‘ { : , . 0 f } ‘ . format ) |
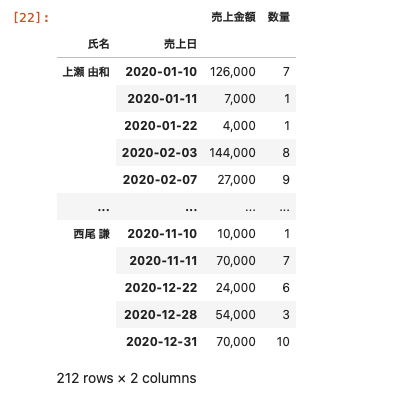
カラムを設定しない場合でも表示することができた
この表はgroupbyと同じような集計結果が表示されている。
つまり、pivot_tableを使うと、groupbyと同じような集計をすることができる
集計結果に項目を追加して表示させる方法
まずは追加する前の集計表を表示させる。
| df_pivot = df.pivot_table ( index = ‘ 氏名 ‘ , columns = ‘ 商品分類 ‘ , values = ‘ 売上金額 ‘ , aggfunc = ‘ sum ‘ ) df_pivot.applymap ( ‘ { : , . 0 f. } ‘ . format ) |
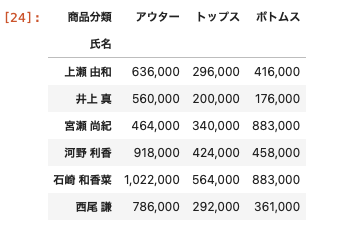
上記の集計表の商品分類の横にそれぞれの商品ごとの売上を合計した項目を追加してみる。
| df_pivot = df.pivot_table ( index = ‘ 氏名 ‘ , columns = ‘ 商品分類 ‘ , values = ‘ 売上金額 ‘ , aggfunc = ‘ sum ‘ , margins = True ) df_pivot.applymap ( ‘ { : , . 0 f } ‘ . format ) |
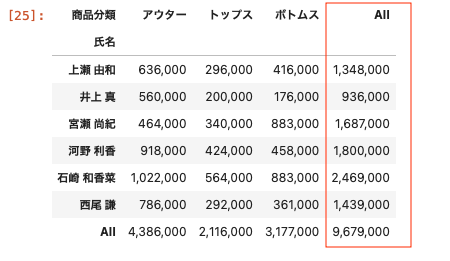
このように合計を行の横に追加することができた。
この記述をすることで、行ごとの合計値を算出することができる
追加した列の名前を変更する方法
任意のAという名前に変更する記述
| df_pivot = df.pivot_table ( index = ‘ 氏名 ‘ , columns = ‘ 商品分類 ‘ , values = ‘ 売上金額 ‘ , aggfunc = ‘ sum ‘ , margins = True , margins_name = ‘ 合計 ‘ ) df_pivot.applymap ( ‘ { : , . 0 f } ‘ . format ) |
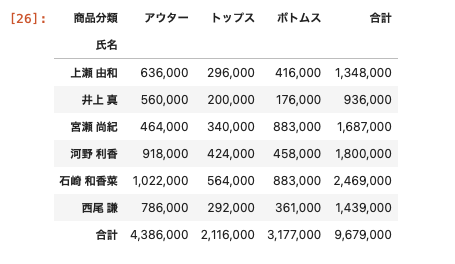
名前がallから合計に置き換わり、スッキリした。
複数の集計を一度に算出する方法
氏名ごとに商品を分類し、商品ごとの売上金額の合計・平均・個数を算出させてみる
| df_pivot = df.pivot_table ( index = ‘ 氏名 ‘ , columns = ‘ 商品分類 ‘ , values = ‘ 売上金額 ‘ , aggfunc = [ ‘ sum ‘ , ‘ mean ‘ , ‘ count ‘ ] ) df_pivot.applymap ( ‘ { : , . 0 f } ‘ . format ) |
集計方法をリストで渡すことで集計結果を算出する。
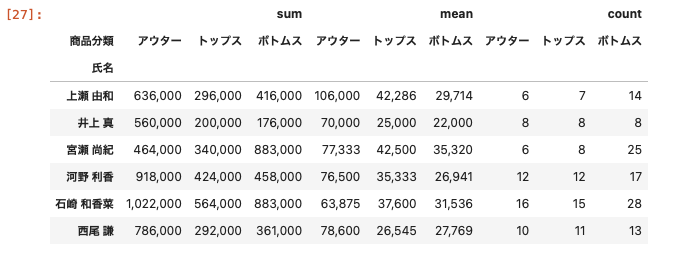
自作関数を使って集計をする方法
集計は、自分で定義した関数を使うこともできる。
今回は、合計の値に消費税(10%)込の金額を表示する自作の関数を作成して表示させる。
まず、高速にリストを計算してくれるライブラリのnumpyをインポートする。
| import numpy as np def cal_tax(s): return np.sum ( s ) * 1.10 df_pivot = df.pivot_table ( index = ‘ 氏名 ‘ , columns = ‘ 商品分類 ‘ , values = ‘ 売上金額 ‘ , aggfunc = cal_tax ) df_pivot.applymap ( ‘ { : , . 0 f } ‘ . format ) |
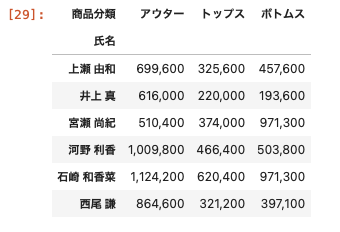
aggfunc = cal_tax:集計方法の部分に自作の関数を代入することで消費税込みの金額で集計することができる。
pivot_tableメソッドとpivotメソッド
pivot_tableメソッドとpivotメソッド
- pivot_tableメソッド:2つのカテゴリのデータを同時に集計してくれる
- pivotメソッド:集計するカラムが値ではなく、文字でも集計することができる
以上のような点がある。
ここからは実際にpivotメソッドを用いて詳しく見ていくことにする。
簡単なデータフレームを作成する
| df = pd.DataFrame ( { ‘ col01 ‘ : [ ‘ A ‘ , ‘ A ‘ , ‘ B ‘ , ‘ B ‘ ] , ‘ col02 ‘ : [ ‘ a ‘ , ‘ b ‘ , ‘ a ‘ , ‘ b ‘ ] , ‘ col03 ‘ : [ 1, 2, 3, 4 ] } ) df |
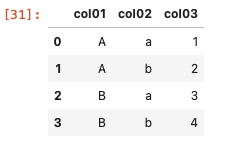
上記のデータフレームを、indexにcol01を指定、columnsにcol02を指定、valuesをcol03に指定した合計を算出してみると、次のようになる
| df_pivot = df.pivot ( index = ‘ col01 ‘ , columns = ‘ col02 ‘ , values = ‘ col03 ‘ ) df_pivot |
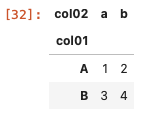
以上のように表示することができた。
これは値を使っているが、今度は文字列を使ったデータフレームを作成して同じことができるかの確認をする
| df = pd.DataFrame ( { ‘ col01 ‘ : [ ‘ A ‘ , ‘ A ‘ , ‘ B ‘ , ‘ B ‘ ] , ‘ col02 ‘ : [ ‘ a ‘ , ‘ b ‘ , ‘ a ‘ , ‘ b ‘ ] , ‘ col03 ‘ : [ ‘ X ‘ , ‘ Y ‘ , ‘ Z ‘ , ‘ W ‘ ] } ) df |
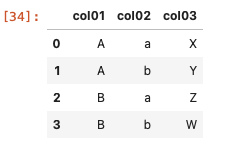
以上のように文字列を使ってデータフレームを作ることができた。
今度はこのデータフレームにindex、columns、valuesそれぞれに文字列の’ col01′ 、’ col02 ‘、’ col03 ‘を指定してpivotメソッドを用いて集計を行う。
| df_pivot = df.pivot ( index = ‘ col01 ‘ , columns = ‘ col02 ‘ , values = ‘ col03 ‘ ) df_pivot |
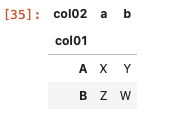
以上の通り、文字列を使った場合でも集計することができることが分かった。
では、ここまでの一連の記述をpivot_tableで記述した場合はどうなるだろうか。
pivot_tableで記述するとどのようになるのかを実際に確認してみる。
| df_pivot = df.pivot_table ( index = ‘ col01 ‘ , columns = ‘ col02 ‘ , values = ‘ col03 ‘ ) df_pivot |
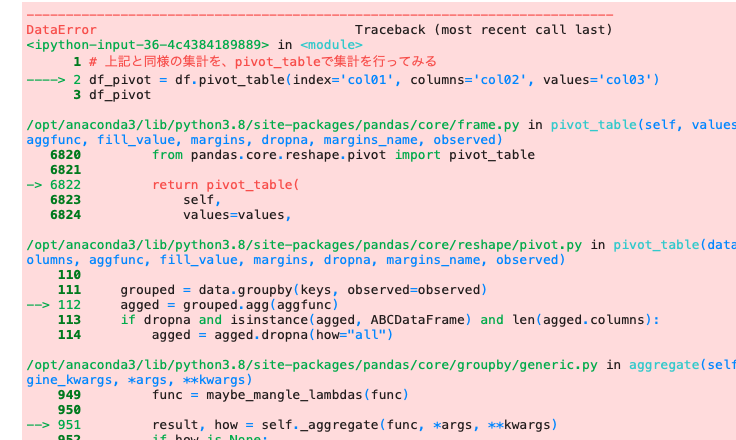
pivotメソッドで記述した際には集計ができたのだが、pivot_tableで記述して実行すると、エラーが発生した。
エラーの内容がなんなのかを見てみると、次のように表示されていた。
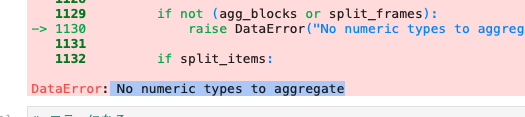
まだ学習段階のため詳細は省きますが、どうやらエラーが出た原因は、集計対象のデータが存在しないと認識されているよーということのようです。
そしてそれはaggfuncに与えるデータが存在していないことを示している。
それでは、pivot_tableで同様の集計をしたい場合にはどのように記述すれば良いか。
aggfuncの引数に最初の値である ‘ first ‘を指定して渡すことで集計が可能になります。
| df_pivot = df.pivot_table ( index = ‘ col01 ‘ , columns = ‘ col02 ‘ , values = ‘ col03 ‘ , aggfunc = ‘ first ‘ ) df_pivot |

以上のようにエラーがでずに集計結果を表示することができた。
まとめ
前回に引き続きデータの集計について学習してきた。
groupbyに続いて今回はExcelでも使う機会の多いpivot_tableについて学習した。
仕事でも集計の際によくピボットテーブルを使うことが多いので、今回の内容についてもしっかりと理解を深めていけるようにする。
後半のピボットテーブルとピボットの違いの部分については正直あまり理解できていない。
ピボットテーブルが使えるようになればgroupbyと同じこともできるようになるので、便利な集計の幅も広がっていくような手応えを感じました。
自作関数についても使えることを確認しました。
自分でも簡単な自作関数を作ってみた上で動作確認をしていけるようにする。
