 Solo-Yase
Solo-Yase 

目次
当記事について
Python学習を独学でいろいろ手を出してきた結果、YouTube学習に落ち着きました。
記事という体裁をとっていますが、動画視聴後の復習での振り返り用として主に自分に向けて記事を書いています。
YouTube学習をはじめた経緯
YouTubeでは数多のプログラマーの方々が非常に有益な情報を発信してくれています。
そんな多くのチャンネルの中からキノコードさんに辿り着いたのは偶然でした。
動画の解説が自分にとっては分かりやすく、初学者に向けて作成してくれている点も視聴開始のきっかけとなりました。
そのため、YouTube学習はキノコードさんのチャンネルに絞って学習しています。
Youtube:キノコード/プログラミング学習チャンネル
SeriesやDataFrameのデータ抽出について
今回は、SeriesやDataFrameの特定の列や行、または特定の条件に一致するデータを抽出する方法について学ぶ。
Pythonでできない抽出はない、と言われているくらいなんでも抽出できる。
使用するデータについては、前回同様政府が発表している1920年〜2015年までの全国の人口推移のデータを使用する。
データの読み込みと設定
| import pandas as pd pd.set_option ( ‘ display.max_columns ‘ , None ) pd.set_option ( ‘ display.max_rows ‘ , 5 ) |
- set_option ( ) :( )でオプションの設定
- None:表示させる列数は制限しないよ、という意味
| df = pd.read_csv ( ‘ data.csv ‘ , encoding = ‘ shift-jis ‘ ) df |
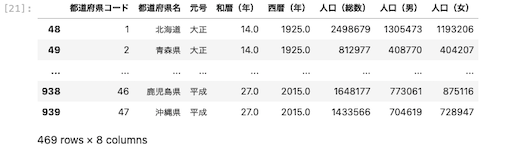
インデックスの行番号を振り直す
基本的にインデックスの行番号は0からはじまる。
+1する設定を行うことで、インデックス番号を1からはじまる番号に振り直すことができる
| df . index = df . index + 1 df |
上図のとおり、インデックス番号が
「0 → 938」から「1 → 939」へと変更された
DataFrame をスライスでデータ抽出を行う
スライスを使って最初の3行を抽出する。
| df [ 0 : 3 ] |

df [ 1 : 3 ] と書いてしまうと、抽出されるのは「2、3」となってしまうことに注意する。
開始位置が0からの場合は一部省略が可能
| df [ : 3 ] |

開始位置の0を省略して記述した場合も同じデータを抽出することができた。
使いやすい書き方で良い。
例1)10〜14行目を抽出する
| df [ 9 : 14 ] |

例2)101行目〜105行目を抽出する
| df [ 100 : 105 ] |
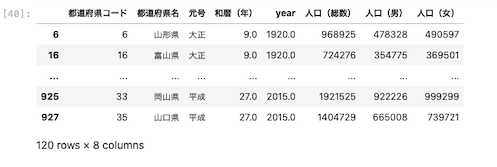
Seriesをスライスでデータ抽出する
DataFrameは1行取り出すとSeriesになる。
人口(総数)の1列をスライスを使用して抽出する。
| df [ ‘ 人口(総数) ‘ ] [ : 5 ] |

Seriesとしてデータを抽出することができた。
SeriesではなくDataFrameのまま抽出する方法
列名を1つ指定してDataFrameからスライスでデータを抽出すると、データ型はDataFrameからSeriesに変化してしまう。
抽出したデータを、DataFrameのまま抽出したい場合には、二重角カッコを使う。
| df [ [ ‘ 人口(総数) ‘ ] ] [ : 5 ] |
複数の列を指定してデータを抽出する
複数の列を指定してデータを抽出するには、二重角カッコ内で、抽出したい列をカンマで区切って記述すれば良い
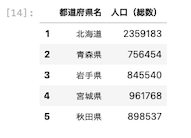
| df [ [ ‘ 都道府県名 ‘ , ‘ 人口(総数) ‘ ] ] [ : 5 ] |
条件に一致する行のみデータを抽出する
真偽値について
たとえば、西暦(年)が2015年に一致する行を抽出する場合には次のような記述をする。
| df [ ‘ 西暦(年) ‘ ] == 2015 |

上記のコードを書くとTrueやFalseが返ってきた。
TrueやFalseを返す値のこと
今回の例では2015年に一致する行がTrue、一致しない行がFalseとして返ってきていることがわかる
以上のことをふまえて、西暦(年)が2015年のDataFrameだけを抽出する場合には、次のようにコードを記述する。
| df [ df [ ‘ 西暦(年) ‘ ] == 2015 ] |

真偽値でTrueとなった部分(2015年)のみを抽出することができた
条件に一致する行のみデータ抽出する:文字列の場合
都道府県名が東京都になっているDataFrameだけを抽出する場合には、次のように記述する
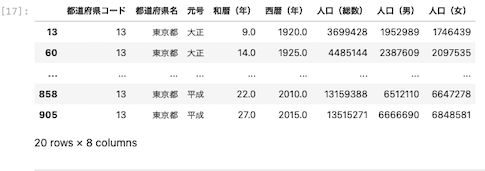
| df [ df [ ‘ 都道府県名 ‘ ] == ‘ 東京都 ‘ ] |
条件に一致する行のみデータ抽出する:10の倍数
西暦(年)が10の倍数のものだけ抽出したい場合には、まず10の倍数をどのように定義すればよいかを考える必要がある。
西暦(年)を10で割り余りが0であれば、それは10の倍数だということができる。
| df [ ‘ 西暦(年) ‘ ] % 10 == 0 |
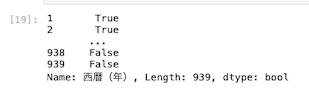
上図のように、西暦(年)を10で割って余りが0のデータはTrueが表示され、余りが0にならないデータについてはFalseが返ってきた。
これをコードに付け加えてあげれば10の倍数のみデータ抽出ができる
| df [ df [ ‘ 西暦(年) ‘ ] % 10 == 0 ] |
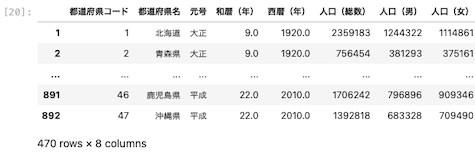
上図のとおり、真偽値でTrueが返ってきたデータのみを抽出することができた
条件に一致しない行のみをデータ抽出する
①Not演算子を使う
| df [ ~ ( df [ ‘ 西暦(年) ‘ ] % 10 == 0 ) ] |
〜(条件式):条件式に一致しないという意味になる
②不等価演算子を使う
Not演算子の記述は不等価演算子を使っても同様にデータを抽出することができる
| df [ df [ ‘ 西暦(年) ‘ ] % 10 != 0 ] |
上図のとおり、Not演算子を使用したときと同じデータを抽出することができた
- !=:不等価演算子(A!=B:AとBは等しくない)
- ==:等価演算子(A==B:AとBは等しい)
2つの条件が「かつ」、「または」条件の場合
(条件1)&(条件2)という形
西暦が2015年で、「かつ」東京都であるデータを抽出する
| df [ ( df [ ‘ 西暦(年) ‘ ] == 2015 ) & ( df [ ‘ 都道府県名 ‘ ] == ‘ 東京都 ‘ ) ] |

(条件1)|(条件2)という形
西暦2010年、または2015年のデータを抽出する
| df [ ( df [ ‘ 西暦(年) ‘ ] == 2010 ) | ( df [ ‘ 西暦(年) ‘ ] == 2015 ) ] |

特定条件でデータを抽出するqueryメソッド
queryメソッドとは
条件に合うデータの行を抽出する関数で、スッキリとした条件式を書くことができる
query(’ 条件式A ‘ )と記述する:条件式Aに合致するデータを抽出する
カラム名に丸カッコ( )があるとqueryメソッドは使えない
カラム名に丸カッコがあるとqueryメソッドを使うことができないので、丸カッコではない名前に変更する必要がある。
西暦(年)を「year」に変更する
rename ( columns = { ‘ 変更前の名前 ‘ : ‘ 変更後の名前 ‘ } )
| df = df.rename ( columns = { ‘ 西暦(年) ‘ : ‘ year ‘ } ) df |

比較演算子を使ってqueryメソッドを記述する
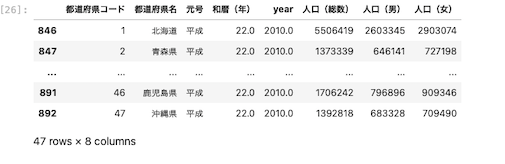
等価演算子:2010年のデータだけを抽出する
| df.query ( ‘ year == 2010 ‘ ) |
比較演算子:2010年を超えるデータのみを抽出する
| df.query ( ‘ year > 2010 ‘ ) |

(or条件)を使ったqueryメソッド
2010年または2015年のデータのみを抽出する
| df.query ( ‘ year == 2010 or year == 2015 ‘ ) |

上図のとおり、2010年または2015年のデータのみを抽出することができた
(and条件)を使ったqueryメソッド
東京都で、かつ2015年のデータを抽出する
| df.query ( ‘ 都道府県名 ‘ == ” 東京都 ” and year == 2015 ‘ ) |

こちらについても条件に合致するデータのみを抽出することができた
特定の値に一致するデータを抽出するisinメソッド
isinメソッドで真偽値を確認する
isinメソッドを使うと特定の値に一致するデータのみを抽出することができる
| df [ ‘ year ‘ ] . isin ( [ 2010 ] ) |

これをデータフレームを取り出すコードに付け加える
| df [ df [ ‘ year ‘ ] . isin ( [ 2010 ] ) |

特定の値に一致するデータを抽出するisinメソッド:複数条件時の場合
| df [ df [ ‘ year ‘ ] . isin ( [ 2010 , 2015 ] ) |

2010年と2015年の条件に合致するデータのみを抽出することができた
isin [ 条件 ] :条件に合うデータのみを抽出する。
isin [ 条件A 、条件B ] : 条件が複数ある場合にはカンマで区切る
特定の値を含むデータを抽出する
部分一致
抽出する文字列に、一部だけが一致しているものを「部分一致」という。
PandasのSeriesのstrメソッドと、抽出したい文字列の条件に応じ
- containsメソッド:部分一致
- startswithメソッド:最初が一致
- endswithメソッド:終わりが一致
これらを組み合わせて使うと、条件に一致するものを抽出することができる。
containsメソッド:特定の文字列が含まれる要素を抽出する
| df [ df [ ‘ 都道府県名 ‘ ] . str . contains ( ‘ 山 ‘ ) ] |
startswithメソッド:特定の値からはじまる要素を抽出する
| df [ df [ ‘ 都道府県名 ‘ ] . str . startswith ( ‘ 大 ‘ ) ] |

endswithメソッド:特定の値で終わる要素を抽出する
| df [ df [ ‘ 都道府県名 ‘ ] . str . endswith ( ‘ 道 ‘ ) ] |

列の最大値・最小値に当てはまる条件のデータを抽出する
maxメソッド:最大値を取得する
| df [ df [ ‘ year ‘ ] == df [ ‘ year ‘ ] . max ( ) ] |
minメソッド:最小値を取得する
| df [ df [ ‘ year ‘ ] == df [ ‘ year ‘ ] . min ( ) ] |
行や列を指定してデータを抽出する方法
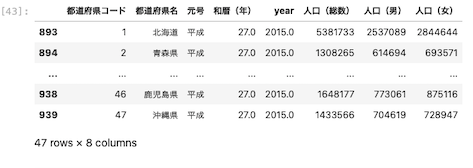
locメソッド:895列目の列名「人口(男)」と「人口(女)」のデータを抽出する
| df . loc [ 895, [ ‘ 人口(男) ‘ , ‘ 人口(女) ‘ ] ] |

まとめ
以前DataFrameとSeriesについて勉強した際には内容がもっさりとしていてあまり理解できていなかった。
今回はDataFrameを使いながら実際でも使う機会がありそうなパターンについていくつか学ぶことができた。
動画についてもわりとすんなりと頭に入ってきたので、今回の動画視聴分については繰り返し自分で色々なパターンでデータ抽出を試してみると理解が深まりそうな手応えがあった。
