 Solo-Yase
Solo-Yase 

目次
当記事について
Python学習を独学でいろいろ手を出してきた結果、YouTube学習に落ち着きました。
記事という体裁をとっていますが、動画視聴後の復習での振り返り用として主に自分に向けて記事を書いています。
YouTube学習を決めた経緯
YouTubeでは数多のプログラマーの方々が非常に有益な情報を発信してくれています。
そんな多くのチャンネルの中からキノコードさんに辿り着いたのは偶然でした。
動画の解説が自分にとっては分かりやすく、初学者に向けて作成してくれている点も視聴開始のきっかけとなりました。
そのため、YouTube学習はキノコードさんのチャンネルに絞って学習しています。
Youtube:キノコード/プログラミング学習チャンネル
そもそもデータベースって何?
データベースとは
データベースとは、特定の条件等に当てはまるデータを収集・管理するシステムのこと
身近なもので例えると、電話帳や住所録、顧客データなどもデータベースに当てはまる。
コンピュータ上でデータベースを管理するシステムのことを、
- DBMS:Database Management System
- RDBMS:Relational Database Management System
ということもある。
データベースでデータを管理するメリット
- 多くのデータをまとめて管理することができる
- 自分の欲しいデータを簡単に探すことができる
- 管理しているデータを編集して使うことができる
PythonではMySQLやPostgresql、Google CloudのBigQueryをデータベースとして接続することができる
この項では、軽量で扱いやすいsqliteを使用する。
非常に軽量で扱いやすいが立派なRDBMSであり、csvやExcelよりも大量のデータを扱うことができる。SQLを使えるようになると、大量データから目的のデータを抽出することも一瞬でできるようになる
データベースを実際に作成してみる
データベース「Test.db」を作成する
| dbname = ‘ TEST.db ‘ conn = sqlite3.connect ( dbname ) conn.close( ) |
うまくコードが書けていれば、TEST.dbというファイルがフォルダに作成される
上記コードの意味としては、「TEST.db」というデータフレームをsqlite3に接続し、接続しているデータフレームを閉じるといったところかな
TEST.dbのファイルが作成されていることが確認できた。
読み込んだcsvデータをデータフレームのテーブルにする
| dbname = ‘ TEST.db ‘ conn = sqlite3.connect ( dbname ) df.to_sql ( ‘test_table ‘ , conn , if_exists = ‘ replace ‘ ) conn.close( ) |
赤下線部は、df(=csvファイル)を、「test_table」という名で、「TEST.db」に接続する、という意味。
テーブルが既に存在する場合にどのような動作をするかを指定する引数のこと。以下、引数の役割
①append:テーブルに追加する
②replace:テーブルを一度削除してから新規で作成する
③fail:既にテーブルが存在するのでエラーを発生させる
sqlからデータを読み込む
| conn = sqlite3.connect ( dbname ) df_db = pd.read_sql ( ‘ SELECT * FROM test_table ‘ , conn ) conn.close ( ) df_db |
sqlからデータを読み込む
‘ SELECT * FROM test_table ‘はSQLのセレクト文というもの。
今回はSQLの動作をメインに記述する。セレクト文などの詳しい内容については割愛する。
Where句を使ったSQL文とトリプルクォートについて
| sql = ‘ ‘ ‘ select * from test_table where 都道府県名 == ” 東京都 “ ‘ ‘ ‘ |
上記コードはテーブルデータの中から、都道府県名が東京都のものを抽出するという意味。
SQL文が長くなると、中身が読みづらく分かりにくくなってしまう。
その場合にはSQL文を「’ ‘ ‘ (トリプルクォート) ‘ ‘ ‘」で囲って記述することで、改行しつつコードを書くことができる。
また、改行して記述することで内容を分かりやすくすることができる。
テーブルデータの検索条件を指定するためのSQL構文のこと。
Where句を使うことで、テーブルデータ内のWhere句が指定する条件で検索対象を絞り込んだりできる。
| conn = sqlite3.connect ( dbname ) df_db = pd.read_sql ( sql, conn ) conn.close ( ) df_db |
セレクト文を使い指定したデータの行数を確認する
| sql = ‘ ‘ ‘ select count ( * ) as cnt from test_table ‘ ‘ ‘ conn = sqlite3.connect ( dbname ) df_db = pd.read_sql ( sql , conn ) conn.close ( ) df_db |
上記コードで、SQLのセレクト文にて指定したデータの行数をカウントするコードを記述。
その後SQLを開き、データを読み込み抽出を行う。

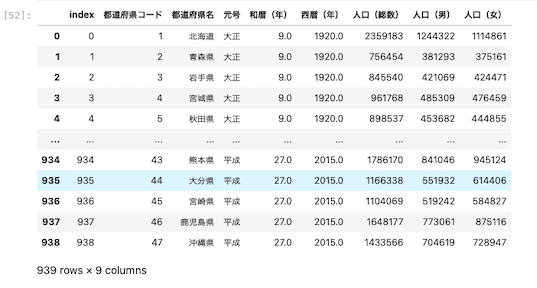
以上のように取り出したデータの行数は939行あることが確認できた。
この方法を使うことで、例えば100万行など膨大なデータ数についてもカウントすることが可能になる(桁数が上がるほどカウントには時間がかかる)
指定したデータの中からさらに絞り込んだデータを抽出する方法
ここでは、上記で抽出した東京都のデータから1920年のデータのみを抽出するコードを記述する。
| sql = ‘ ‘ ‘ select * from test_table where 都道府県名 == ” 東京都 ” and 西暦(年) == ” 1920.0 “ ‘ ‘ ‘ |
| conn = sqlite3.connect ( dbname ) df_db = pd.read_sql ( sql , conn ) conn.close ( ) df_db |

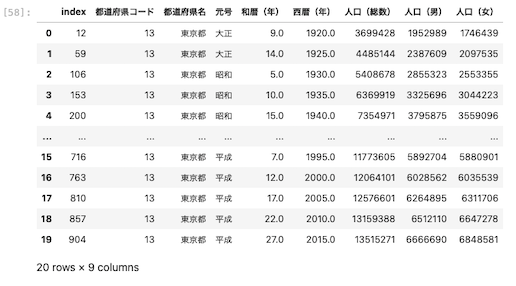
上記の通り指定した「1920年の東京都のデータ」のみを取り出すことができた。
まとめ
今回はデータベースを作るということを勉強した。
詳しい内容については置いといて、全体像というかデータベースがあると便利なんだな、ということがざっくりと理解できた気がした。
SQLについては正直あまり理解できていない。
別の動画で見た記憶があり、SQLはプログラミング言語ではなくデータベースにしか命令をすることができない、いわゆる「特殊な言語」ということ。
今回の動画でも出てきたセレクト文というものが、この命令文にあたるのだということは理解できた。
セレクト文自体は1文簡潔で読むだけでもなんとなく意味が理解できるなぁと感じた。
SQLを使えるようになると膨大なデータを扱うことができることから、Pythonと並行して少し勉強しようかと思う。
補足
この項はプログラミング言語PythonのライブラリであるPandasの学習復習用に整理したものである。
YouTubeチャンネル/キノコードさんが解説する動画を視聴し、あとで自分で見直しながらコードを書いていけるように内容をまとめたものである。
