 Solo-Yase
Solo-Yase 

目次
当記事について
Python学習を独学でいろいろ手を出してきた結果、YouTube学習に落ち着きました。
記事という体裁をとっていますが、動画視聴後の復習での振り返り用として主に自分に向けて記事を書いています。
YouTube学習を決めた経緯
YouTubeでは数多のプログラマーの方々が非常に有益な情報を発信してくれています。
そんな多くのチャンネルの中からキノコードさんに辿り着いたのは偶然でした。
動画の解説が自分にとっては分かりやすく、初学者に向けて作成してくれている点も視聴開始のきっかけとなりました。
そのため、YouTube学習はキノコードさんのチャンネルに絞って学習しています。
Youtube:キノコード/プログラミング学習チャンネル
シリーズとは
データフレームとは
Pandasで扱うデータ構造にはDataFrameとSeriesの2つがある。
- DataFrame:Excelのように行と列で成り立つイメージ
- Series:DataFrameから1列取り出したときにできる型でもあり、Pythonのリストにindexがくっついているイメージ
DataFrameから1列抽出するとSeriesになり、DataFrameはSeriesをまとめたもの、ということができる。
Seriesを理解することは、DataFrameを理解するということでもある
シリーズの作成方法
- リストから作成する方法
- numpyを使って作成する方法
- 辞書型データを使って作成する方法
シリーズ、3つの作成方法
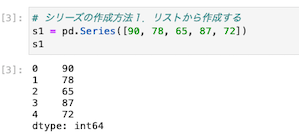
①リストから作成する方法
| import pandas as pd s1 = pd.Series([90, 78, 65, 87, 72]) s1 |
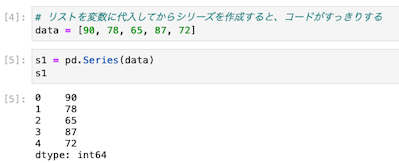
変数にリストを代入してからシリーズを作成すると、コードがすっきりする
| data = [90, 78, 65, 87, 72] s1 = pd.Series(data) s1 |
②Numpyを使って作成する方法
| import numpy as np np.arange(1, 10, 2) |
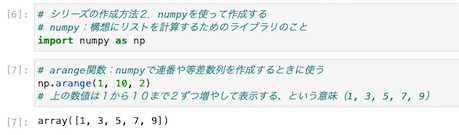
Numpy:高速にリストを計算するためのライブラリのこと
aranege関数:Numpyで連番や等差数列を作成するときに使う
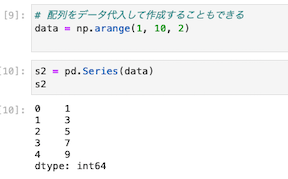
配列を変数に代入して作成すると、コードがスッキリする
| data = np.arange(1, 10, 2) s2 = pd.Series(data) s2 |
シリーズのデータ型を取得する
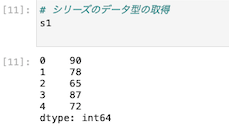
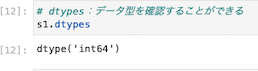
データ型を確認することができる
| s1.dtyeps |
| dtype(‘int64’) |
s1のシリーズは整数型(int64)であることが示されている
indexを取得する方法
| s1.index |
| RangeIndex(start=0, stop=5, step=1) |
s1のシリーズのインデックスは、0からはじまり5で終わり(5のひとつ前の4)、1ずつ増えているという意味らしい
indexを指定する
| s1.index = [‘sato’, ‘suzuki’, ‘takahashi’, ‘tanaka’, ‘ito’] s1 |
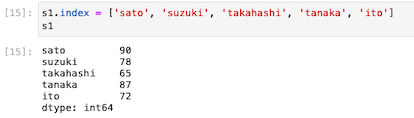
このように、0から4の連番からindex名へ変更ができた
インデックス名の変更後にあらためてs1のインデックスを確認すると、

さきほどはint型であると表示されたが、名前を変更したのでobject型に変わっていることが分かる
③辞書型データを使って作成する方法
| dict01 = {‘sato’:90, ‘suzuki’:78, ‘takahashi’:65, ‘tanaka’:87, ‘ito’:72} s3 = pd.Series(dict01) s3 |
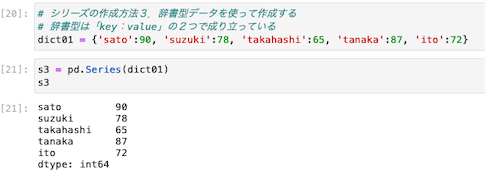
シリーズの値を取得する
| s1.values |
| array([90, 78, 65, 87, 72]) |
インデックスを指定して取得する
| s1[‘suzuki’] |
| 78 |
インデックス番号を指定して値を取得する
| s1[1] |
| 78 |
辞書(key:value)の組み合わせで成り立つ
・valuesを使って値を取得する( s1.values )
・インデックス名を指定して値を取得する( s1[‘suzuki’] )
・インデックス番号を指定して値を取得する( s1[1] )
リストでインデックスを指定して複数の値を取得する
| s1 [ [ ‘ suzuki ‘ , ‘ tanaka ‘ ] ] |
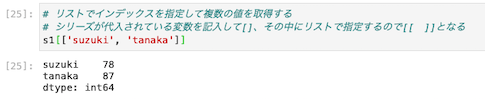
角カッコが2重になっていることに注意する
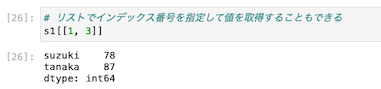
リストでインデックス番号を指定して値を取得する
比較演算子を使った値の抽出方法
TrueとFalse
比較演算子を使い、該当する値を割り出す。
- A > B:Bより大きい
- A >=B:B以上
- A < B:Bより小さい
- A <=B:B以下
該当する箇所はTrueと表示され、該当しない箇所はFalseが返ってくる
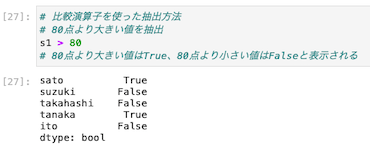
TrueとFalseの2種類の値をとるデータ型のこと。真偽値ともいう。
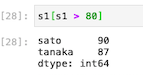
80より大きいTrueが返ってきたsatoさんとtanakaさんの値が返ってきたことがわかる
要素数を取得する
| s1.size |
| len(s1) |
上記どちらを使っても要素数を取得できる
オブジェクトの要素数や文字数を取得するときに使う
indexとデータ部分に名前をつける方法
シリーズはindexとデータ部分で構成されているので、各々名前をつけることができる
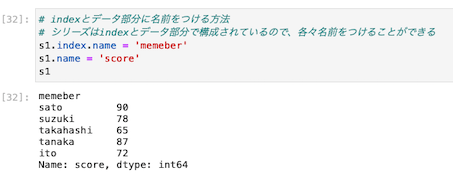
上記の通り、インデックス名はmemberとなり、データ部分はscoreと表示されており、データ型はint64(整数型)であることがわかる。
シリーズの四則演算
四則演算が可能
- s1 + 2 : s1に2を加算する
- s1 – 2 : s1から2を減算する
- s1 * 2 : s1を二乗する
- s1 / 2 : s1を除算する
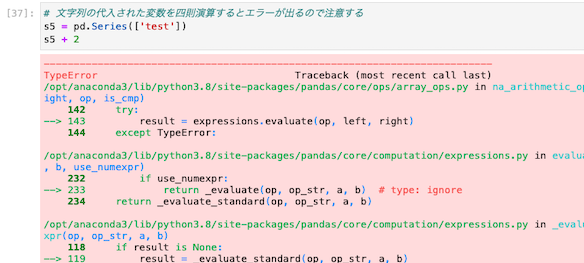
文字列を四則演算するとエラーが出る
シリーズ同士で足し算をする


s2にインデックス名を付けた上で足し算をしてみる
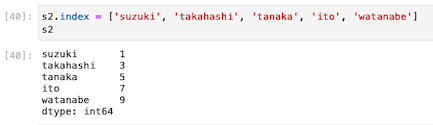

s2にインデックス名を付加したのが上図。共通している名前と片方にしかない名前がある。
| s1 + s2 |
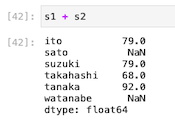
s1とs2の両方に共通しているインデックス名のデータは加算された。
片方にしかないデータついてはNaN(=Not A Number)と表記された。
欠損値の有無を確認する
| s1.hasnans |
| False |
欠損値があるときにはTrue、欠損値がないときにはFalseが表示される
上記の結果から、s1データ部分に欠損値はないことが分かる。
hasnansで欠損値が出るようにNoneを設定して確認する
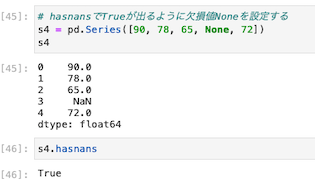
欠損値をわざと作ったリストを確認すると、Trueと返ってきた。
欠損値の箇所を確認する
どの部分に欠損値があるかを確認する。
欠損値がある場所は、Trueと表示される。
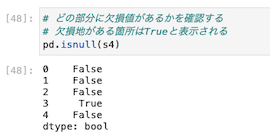
このようにどの部分で欠損値があるのかが明確になった。
データフレームを作成する
データフレームとシリーズ
| df = pd.DataFrame ( [ [ 1, 2, 3 ] , [ 4, 5, 6 ] , [ 7, 8, 9 ] ] , columns = [ ‘ col01 ‘ , ‘ col02 ‘ , ‘ col03 ‘ ] , index = [ ‘ idx01 ‘ , ‘ idx02 ‘ , ‘ idx03 ‘ ] ) df |
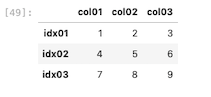
作成した上記のデータフレームから1列取り出すと、シリーズになる。
ためしにcol01の列を取り出してみる
| df [ ‘ col01 ‘ ] |

念のために取り出したcol01列のデータ型を確認する。
| type(df[ ‘ col01 ‘ ]) |
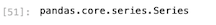
念のためデータ型を確認してみたが、シリーズ型になっていることが確認できた
データフレームにシリーズを追加する方法
| s5 = pd . Series ( { ‘ idx01 ‘ : 10 , ‘ idx02 ‘ : 11 , ‘idx03 ‘ : 12 } ) s5 |
s5というシリーズを新たに作成したものを、col04に代入する。
| df [ ‘ col04 ‘ ] = s5 df |

データフレームに追加してデータをつけたすことができた。
データフレーム内に存在しないインデックス名のシリーズを追加するとどうなるか
| s6 = pd . Series ( { ‘ idx03 ‘ : 13 , ‘ idx04 ‘ : 14 , ‘ idx05 ‘ : 15 } ) s6 |
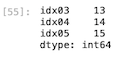
シリーズは問題なく作成できた。このシリーズをcol05としてデータフレームに追加すると、どうなるか。
| df [ ‘ col05 ‘ ] = s6 df |
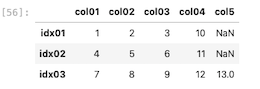
上記の通り、idx03だけは存在するためデータフレームに追加されたが、存在しないidx04とidx05についてはデータフレームに追加されなかった。
また、idx01とidx02にはNaNと表示されて欠損値となった。
時系列データの取り扱い
date_range関数で時系列データを作成する
| dates = pd . date_range ( ‘ 2000 / 01 / 01 ‘ , periods = 5 , freq = ‘ D ‘ ) dates |

2000/01/01から5つのDatetimeIndexを作成した。
文中の freq = ‘ D ‘は、時系列データの頻度を表す引数。
今のところ詳しい使い方については不明。
D:毎日
B:毎営業日(月曜日ー金曜日)
W:毎週(日曜日始まり)
M:月末ごと
SM:15日と月末ごと
Q:四半期末ごと
AまたはY:年末ごと
date型はdatetimeインデックスとなる
| type ( dates ) |

インデックス名を時系列データに指定する

上図ではインデックス名には人名が付されているが、これを時系列データに変更する
| s1 . index = dates s1 |
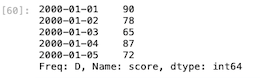
このように時系列データに置き換えが成功した。
このインデックス名が時系列データになると特殊な集計が可能になるとのことで、今後新たな集計方法についても学んでいく予定。
まとめ
前回に引き続いて、今回はシリーズについて勉強した。
前回学習したデータフレームについても同様だが、現時点ではこの2つをどのように役立てていくのかがざっくりしすぎていてあまりよく分かっていない。
データ集計などを行うようになるとまた少し違うのかもしれないけれど、現時点では漠然と「ふーん、そうなんだね〜」くらいの感覚でしか理解できていない気がする。
補足
この項はプログラミング言語PythonのライブラリであるPandasの学習復習用に整理したものである。
YouTubeチャンネル/キノコードさんが解説する動画を視聴し、あとで自分で見直しながらコードを書いていけるように内容をまとめたものである。

